
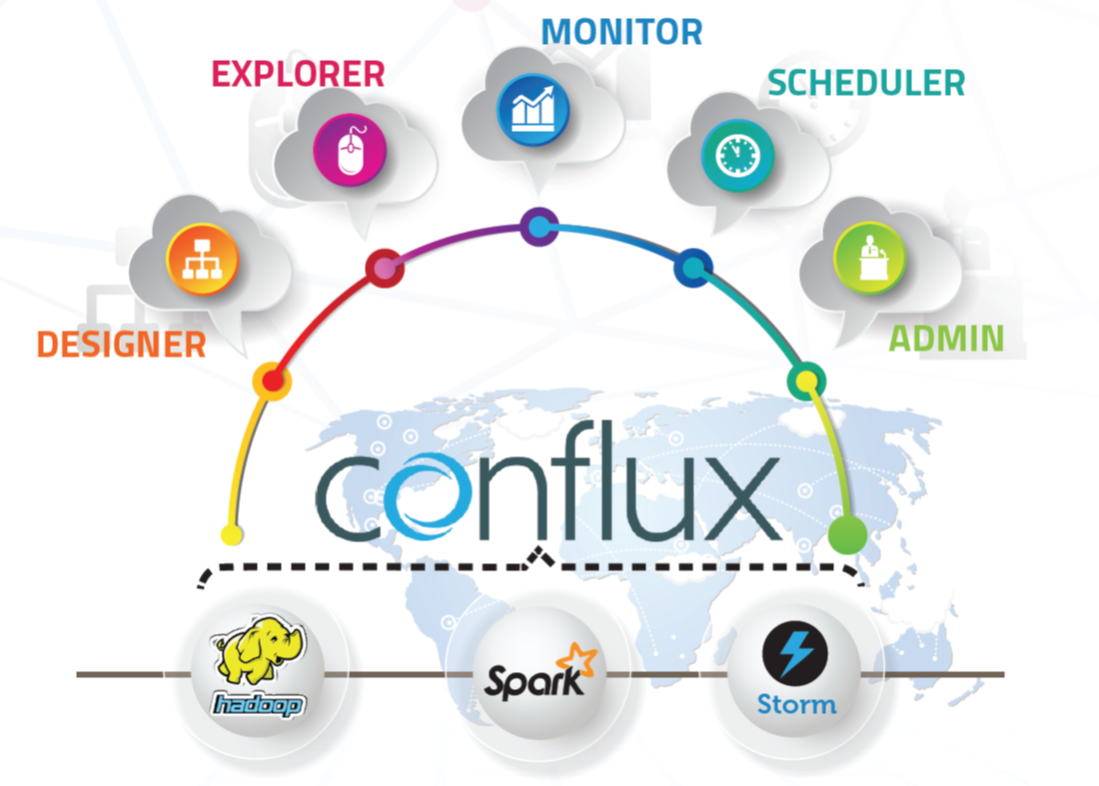
Data-driven workflows are the life and existence of big data professionals everywhere: data scientists, data analysts, and data engineers. We perform all types of data functions in these workflow processes: archive, discover, access, visualize, mine, manipulate, fuse, integrate, transform, feed models, learn models, validate models, deploy models, etc. It is a dizzying day’s work. We start manually in our workflow development, identifying what needs to happen at each stage of the process, what data are needed, when they are needed, where data needs to be staged, what are the inputs and outputs, and more. If we are really good, we can improve our efficiency in performing these workflows manually, but not substantially. A better path to success is to employ a workflow platform that is scalable (to larger data), extensible (to more tasks), more efficient (shorter time-to-solution), more effective (better solutions), adaptable (to different user skill levels and to different business requirements), comprehensive (providing a wide scope of functionality), and automated (to break the time barrier of manual workflow activities).
(continue reading here … http://www.bigdatanews.com/group/bdn-daily-press-releases/forum/topics/apervi-s-conflux-gives-a-big-boost-to-a-confluence-of-big-data-wo)
Follow Kirk Borne on Twitter @KirkDBorne