Pure Storage empowers enterprise AI with advanced data storage technologies and validated reference architectures for emerging generative AI use cases.
Summary
AI devours data. With award-winning AI-ready infrastructure, an AI data platform, and collaboration with NVIDIA, Pure Storage is delivering solutions and services that enable organizations to manage the high-performance data and compute requirements of enterprise AI.
AI Then and AI Now
They (some wise anonymous folks out there) say that there is a time and place for everything. They also say there is a season for every purpose. I believe that the time, place, and season for artificial intelligence (AI) data platforms have arrived. To see this, look no further than Pure Storage, whose core mission is to “empower innovators by simplifying how people consume and interact with data.”
In the past, it was sufficient to bring order to the randomness of enterprise data collection through applications of technology resources (databases and storage devices) that were aimed primarily at organizing, storing, indexing, and managing enterprise information assets for single purposes or single business units. However, this data was still left mostly unexploited for its maximum potential and enterprise-wide business value.
Also in the past, it was sufficient for business automation to consist primarily of rigid rule-based robotic non-adaptive repetition of processes and fixed tasks, requiring very little (if any) new knowledge input (i.e., live data consumption) or real-time adaptation to changing business conditions.
And also in the past, it was sufficient for AI to be relegated to academic researchers or R&D departments of big organizations who mostly produced research reports or journal papers, and not much else.
Fast-forward to 2024 and we see a totally different landscape: massive data sets feeding dynamic cross-enterprise processes, increasing automation and dynamic adaption of complex multi-step tasks, and ubiquitous value-producing applications of AI. In particular, in the past year, generative AI has played a major role in the explosive development and growth of these transformations within enterprises.
Pure Storage Meets the Demands of Enterprise AI
To support, sustain, and assure the continued success and cost-effectiveness of the enormous data-fueled AI-powered transformations in such a rapidly changing environment, Pure Storage has stepped up their delivery of an incredible array of award-winning AI-ready infrastructure (AIRI//S™) products and services with an AI data platform that provides the fundamental AI environment for enterprise data management (storage, access, orchestration, delivery), hyperscaled AI training, and AI inference on demand (on-prem, in data centers, at edge sites, and in micro edge devices).
One example of Pure Storage’s advantage in meeting AI’s data infrastructure requirements is demonstrated in their DirectFlash® Modules (DFMs), with an estimated lifespan of 10 years and with super-fast flash storage capacity of 75 terabytes (TB) now, to be followed up with a roadmap that is planning for capacities of 150TB, 300TB, and beyond. Another example is Pure Storage’s FlashBlade® which was invented to help companies handle the rapidly increasing amount of unstructured data coming into greater use, as required in the training of multi-modal AI models. One more example is Pure Storage’s development of non-disruptive upgrades (NDUs), a feature of Pure Storage’s architecture that permits upgrades and expansion of the data infrastructure with no impact on data availability or performance, and with no downtime or data migrations.
Pure Storage’s Announcements at GTC 2024
The preceding examples are industry-leading and exemplary, and yet there’s still more. At the NVIDIA GTC 2024 conference, Pure Storage announced so much more! Here are a few more details on some of those announcements.
A Data Platform for AI
Data is the fuel for AI, because AI devours data—finding patterns in data that drive insights, decisions, and action. Ease of data orchestration (ingest, cleaning, transformation, discovery, access, exploration, delivery, training, inference, deployment) is essential for data-devouring AI products and services. A data platform for AI is key to innovation and long-term affordability, scalability, sustainability, and advancement of enterprise AI applications. Anything less than a complete data platform for AI is a deal-breaker for enterprise AI. Pure Storage provides the ideal data platform for AI, as it provides unified storage for structured and unstructured data and provides enterprise data services for Kubernetes, supporting the entire AI data pipeline, because storage matters!
At GTC 2024, Pure demonstrated the features of their data platform for AI, specifically highlighting these benefits and features of the platform: (a) Helps organizations accelerate model training and inference; (b) Improves operational efficiency for AI/IT infrastructure teams, as well as AI/ML developers and engineers; (c) Delivers cost and energy efficiency as an enterprise scales their AI operations; and (d) Provides an AI storage platform that delivers ultimate reliability and is built to handle all future AI storage needs.
Optimizing GenAI Apps with RAG—Pure Storage + NVIDIA for the Win!
One of the most popular techniques associated with generative AI (GenAI) this past year has been retrieval-augmented generation (RAG). RAG is the essential link between two things: (a) the general large language models (LLMs) available in the market, and (b) a specific organization’s local knowledge base. In deep learning applications (including GenAI, LLMs, and computer vision), a data object (e.g., document, image, video, audio clip) is reduced (transformed) to a condensed vector representation using deep neural networks. The knowledge base then becomes the comprehensive collection of these condensed representations of the enterprise business data repositories, stored in vector format in a vector database—Vector DB being another major data technology development finding widespread adoption this past year.
As a consequence of these activities, RAG provides the bespoke use case-specific context to an organization’s proprietary GenAI LLM applications. This contextualization of the GenAI LLM is not only enterprise-specific, local, and customized, but it is also proprietary—maintaining the privacy and security of the GenAI LLM application within the security firewalls and policies of that organization. Additionally, RAG ensures the use of an organization’s most recent data while eliminating the need for constant retraining of the LLMs. Pure Storage has worked with NVIDIA (GPU memory and GPU servers) to boost the speed, accuracy, and on-prem power of such enterprise GenAI LLM applications. Here are some specific documented results:
(a) “NVIDIA GPUs are used for compute and Pure Storage FlashBlade//S provides all-flash enterprise storage for a large vector database and its associated raw data. In a specific case [presented at GTC], the raw data consisted of a large collection of public documents, typical of a public or private document repository used for RAG.”
Pure Storage’s RAG pipeline, in conjunction with NVIDIA GPUs and NVIDIA’s NeMo Retriever collection of GenAI microservices, ensures accuracy, currency, privacy, and relevance of proprietary enterprise LLMs. Time to insight and time to action in AI applications are faster and better with Pure Storage.
OVX Validated Reference Architecture for AI-ready Infrastructures
First question: What is OVX validation? OVX is NVIDIA’s standard validation paradigm for computing systems that combine high-performance GPU acceleration, graphics, and AI with fast, low-latency networking that are used to design and power complex 3D virtual worlds and digital twins that are transforming how businesses design, simulate, and optimize complex systems and processes. In this fantastic emerging realm of breathtaking technological achievements and innovations, Pure Storage has achieved OVX validation of their reference architecture for AI-ready infrastructures. At this stage, OVX validation applies directly to the increasing business demand for GenAI workloads (including RAG, LLMs, knowledge bases, and Vector DB), full-stack ready-to-run enterprise AI infrastructure, and local proprietary custom data + AI compute, storage, and networking solutions. Note: When you see “full-stack,” read “Pure Storage + NVIDIA working together seamlessly.”
Second question: What about technical debt and the cost of “lift and shift” to these new AI-ready architectures? For Pure Storage, OVX validation also certifies that Pure Storage’s AI-ready infrastructure will run on NVIDIA GPUs and on other vendors’ servers, which is a great savings on technical debt for those organizations that operate diverse server farms. OVX validation complements Pure Storage’s certified reference architecture for NVIDIA DGX BasePOD that was announced last year as well as their FlashStack® for AI Cisco Validated Designs announced here.
Since one of the only certainties about the future is its uncertainty, it is a great benefit that Pure Storage Evergreen//One™ provides storage-as-a-service (STaaS) guarantees and enables future-proof growth with non-disruptive upgrades. That means that Pure Storage owns the hardware (“the end user doesn’t pay for it”), but the end user buys a subscription to the storage with the same agility and flexibility of public cloud storage, and with all the security, proprietary protection, and performance of on-prem all-flash sustainable infrastructure. This is Pure Storage’s SLA-guaranteed cloud-like STaaS!
More Pure Storage Announcements at GTC 2024
Pure Storage’s RAG development (described earlier) is accelerating successful AI adoption across vertical industries. Pure Storage is accomplishing this by creating vertical-specific RAGs in collaboration with NVIDIA. First, “Pure Storage has created a financial services RAG solution to summarize and query massive data sets with higher accuracy than off-the-shelf LLMs. Financial services institutions can now gain faster insight using AI to create instant summaries and analysis from various financial documents and other sources.” Pure Storage will soon release additional RAGs for healthcare and the public sector.
Expanded investment in the AI partner ecosystem: Pure Storage is further investing in its AI partner ecosystem with NVIDIA, engaging in new partnerships with independent software vendors (ISVs). Some of these investments are aimed at optimizing GPU utilization through advanced orchestration and scheduling, and others enable machine learning teams to build, evaluate, and govern their model development lifecycle. Additionally, Pure Storage is working closely with numerous AI-focused resellers and service partners to further operationalize joint customer AI deployments.
Looking at AI Now and at What’s Next
As the award-winning leader in AI-ready (and future-ready) data infrastructure, Pure Storage is collaborating with NVIDIA to empower their global customers with a proven framework to manage the high-performance data and compute requirements that these enterprises need to drive successful AI deployments, both now and into the future. Every technical leader, line of business (LOB) leader, VP of Infrastructure for AI, VP of AI/Data Science, and CDO/CTO/CAIO can benefit right now from these technologies and services.
To put all of Pure Storage’s recent accomplishments, products, services, and solutions into a single statement, I would say that Pure Storage’s primary purpose (their North Star) is to guide and accelerate their customers’ adoption of AI through the Pure Storage platform for AI.
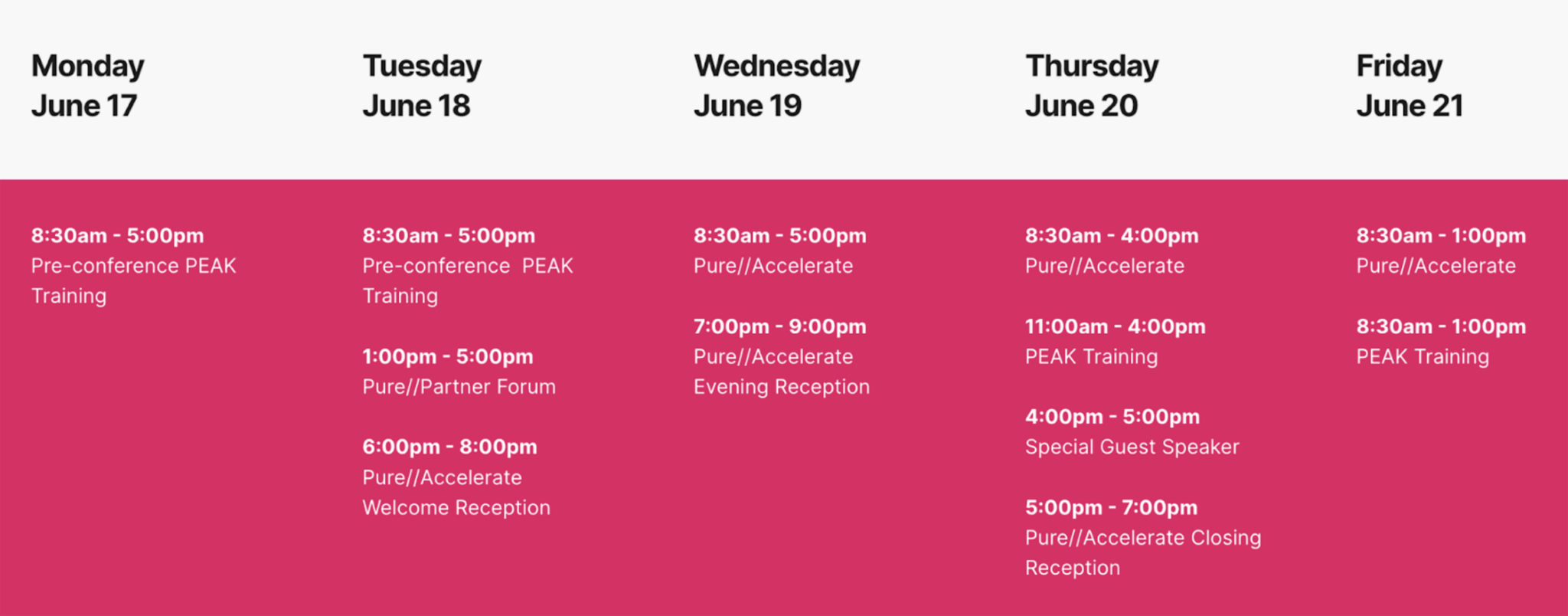
To learn more about all of this, make connections, learn new skills, and get ready for what’s next in this rapidly evolving season of AI, be sure to register and attend the Pure//Accelerate® 2024 live event June 18-21, 2024, at Resorts World Las Vegas. The event will have a special track on “Today’s and Tomorrow’s Applications of AI.” Don’t miss it!
Register Now for Pure//Accelerate 2024
Drive your data success at Pure//Accelerate® at Resorts World Las Vegas from June 18-21. This is the premier event to make connections, learn new skills, and get ready for what’s next. Here’s a sneak peek of what to expect:
Decades (at least) of business analytics writings have focused on the power, perspicacity, value, and validity in deploying predictive and prescriptive analytics for business forecasting and optimization, respectively. These are primarily forward-looking actionable (proactive) applications.
There are other dimensions of analytics that tend to focus on hindsight for business reporting and causal analysis – these are descriptive and diagnostic analytics, respectively, which are primarily reactive applications, mostly explanatory and investigatory, not necessarily actionable.
In the world of data there are other types of nuanced applications of business analytics that are also actionable – perhaps these are not too different from predictive and prescriptive, but their significance, value, and implementation can be explained and justified differently. Before we dive into these additional types of analytics applications, let us first consider a little pedagogical exercise with two simple evidence-based inferences.
(a) In essentially 100% of cases where an automobile is involved in an accident, the automobile had four wheels on the car prior to the accident.
(b) In 100% of divorce cases, the divorcing couple was married prior to the divorce.
What is the point of those obvious statistical inferences? The point is that the 100% association between the event and the preceding condition has no special predictive or prescriptive power. Hence, prior knowledge of these 100% associations does not offer any actionable value. In statistical terms, the joint probability of event Y and condition X co-occurring, designated P(X,Y), is essentially the probability P(Y) of event Y occurring. The probability of the condition X occurring, P(X), is irrelevant since the existence of the precondition X is implicitly present by default.
Okay, those examples represent two remarkably uninteresting cases. Even when similar sorts of inferences occur in a business context, they have essentially zero value. How do predictive and prescriptive analytics fit into this statistical framework?
Using the same statistical terminology, the conditional probability P(Y|X) (the probability of Y occurring, given the presence of precondition X) is an expression of predictive analytics. By exploring and analyzing the business data, analysts and data scientists can search for and uncover such predictive relationships. This is predictive power discovery. Another way of saying this is: given observed data X, we can predict some outcome Y. Or more simply: given X, find Y.
Similarly (actually, conversely), we can use the conditional probability P(X|Y) (which is the probability that the precondition X exists, given the existence of outcome Y) as an expression of prescriptive analytics. How does that work in practice? By exploring and analyzing business data, analysts and data scientists can search for and uncover the conditions (causal factors) that have led to different outcomes. So, if the business wants to optimize some outcome Y, then data analysts will be tasked with finding the conditions X that must be implemented to achieve that desired outcome. This is prescriptive power discovery. Another way of saying this is: given some desired optimal outcome Y, what conditions X should we put in place. Or more simply: given Y, find X. Note how this simple mathematical expression of prescriptive analytics is exactly the opposite of our previous expression of predictive analytics (given X, find Y).
Here are a few business examples of this type of prescriptive analytics: Which marketing campaign is most efficient and effective (has best ROI) in optimizing sales? Which environmental factors during manufacturing, packaging, or shipping lead to reduced product returns? Which pricing strategies lead to the best business revenue? What equipment maintenance schedule minimizes failures, downtime (mean time to recovery), and overall maintenance costs?
Now that we have described predictive and prescriptive analytics in detail, what is there left? What are the three types of actionable (and valuable) business analytics applications that are not called predictive or prescriptive? They are sentinel, precursor, and cognitive analytics. Let’s define what these are.
Sentinel Analytics – in common usage, the sentinel is the person on the guard station who is charged with watching for significant incoming or emergent activity. In practice, all activity is being observed and a decision is made as to whether any particular activity requires some sort of triage: sounding an alarm, or sending an alert to decision-makers, or doing nothing.
In the enterprise, sentinel analytics is most timely and beneficial when applied to real-time, dynamic data streams and time-critical decisions. For example, sensors (including internet of things devices and APIs on data networks) can be deployed with logic (analytics, statistical, and/or machine learning algorithms) to monitor and “watch” business systems and processes for emerging patterns, trends, behaviors, unusual operating modes, and anomalies that might be indicators of activities that require business attention, decisions, and/or action.
Precursor Analytics – in common usage, precursors are the early-warning indicators (harbingers, forerunners) of something else more serious or catastrophic that is about to come. We occasionally hear about earthquake precursors (increased levels of radon in groundwater), tidal wave precursors (a deep ocean earthquake), and cyber-attack precursors (phishing incidents). Precursor analytics is related to sentinel analytics. The latter (sentinel) is associated primarily with “watching” the data for interesting patterns that might require action, while precursor analytics is associated primarily with training the business systems to quickly identify those specific “learned” patterns and events that are known to be associated with high-risk events, thus requiring timely attention, intervention, and remediation.
In these applications, the data science involvement includes both the “learning” of the most significant patterns to alert on and the improvement of their models (logic) to minimize false positives and false negatives. The analytics triage is critical, to avoid alarm fatigue (sending too many unimportant alerts) and to avoid underreporting of important actionable events. One could say that sentinel analytics is more like unsupervised machine learning, while precursor analytics is more like supervised machine learning. That is not a totally clean separation and distinction, but it might help to clarify their different applications of data science.
The counterexample to the supervised learning explanation of precursor analytics is a “black swan” event – a rare high-impact event that is difficult to predict under normal circumstances – such as the global pandemic, which led to the failure of many predictive models in business. Broken models are definitely disruptive to analytics applications and business operations. Paradoxically, the precursor was actually predictive in a disruptive anti-predictive sort of way, which brings us right back to P(Y|X), or maybe it should be stated as P(“not Y”|X) where X is the black swan event (i.e., the predicted outcome Y from existing models will not occur in this case). As such, the global pandemic serves as a warning (a harbinger of disruption) and consequently as a “training example” to businesses for any future black swans.
Cognitive Analytics – this analytics mindset approach focuses on “surprise” discovery in data, using machine learning and AI to emulate and automate the cognitive abilities of humans. The goal is to discover novel, interesting, unexpected, and potentially valuable signals in the flood of streaming enterprise data. These may not be high-risk discoveries, but they could be high-reward discoveries. How does that resemble human cognitive abilities? Curiosity! Being curious about seeing something “funny” that you didn’t expect, thereby putting a “marker” in the data stream: “Look here! Pay attention! Ask questions about this!”
Cognitive analytics is basically the opposite of descriptive analytics. In descriptive analytics, the task is to find answers to predetermined business questions (how much, how many, how often, who, where, when), whereas cognitive analytics is tasked with finding the business questions that should be asked. Descriptive: find the right answers in the data. Cognitive: find the right questions in the data. Cognitive analytics can then be viewed as a precursor to diagnostic analytics, which is the investigative stage of analytics that answers the questions raised by cognitive analytics (“Why did this happen?”, “Why are we seeing this pattern in our data?”, “What is the business impact of this trend, anomaly, behavior?”, “What is our next-best action as a result of this?”, “That’s funny! What is that?”).
None of these descriptions of the 3 “new” analytics applications are meant to declare that these are completely distinct and different from the “big 4” analytics applications that we have known for many years (Descriptive, Diagnostic, Predictive, Prescriptive). But the differences between the “big 4” and the “new 3” are in the nuanced business applications of these analytics in the enterprise and in the types of inferences that the data scientists are asked to derive from the business data.
Deploying these analytics in the cloud further expands their accessibility, democratization, enterprise-wide acceptance, broad advocacy, and ultimate business value. Blending automated analytics products (coming from the sentinel, precursor, and cognitive applications) with human-in-the-loop inquisitiveness, curiosity, creativity, out-of-the-box thinking, idea generation, and persistence can transform any organization into a data analytics powerhouse through an analytic culture revolution. This is more imperative than ever, as a global survey of analytics executives has revealed:
“Companies have been working to become more data-driven for many years, with mixed results.”
“Right now, the biggest challenge for organizations working on their data strategy might not have to do with technology at all.”
“Corporate chief data, information, and analytics executives reported that cultural change is the most critical business imperative.”
“Just 26.5% of organizations report having established a data-driven organization.”
“91.9% of executives cite cultural obstacles as the greatest barrier to becoming data driven.”
Where do organizations get help to overcome these challenges? Microsoft delivers what its clients need to help them grow their top line with cloud-based analytics. Microsoft’s cloud-based analytics products and services propel business insights, innovation, and value from enterprise data, with all of the dimensions of analytics applications brought into the game. Specifically, cloud analytics (accessing and inferencing on multiple diverse business datasets across business units) for a wide variety of enterprise applications can sharpen the workforce’s focus on value and growth, including: forward-looking insights through predictive, sentinel, and precursor analytics; novel recommendations; rich customer engagement; analytic product innovation; resilience through prescriptive analytics; surprise discovery in data, asking the right questions, and exploring the most insightful lines of inquiry through cognitive analytics; and more.
Microsoft Azure Cloud extends ease-of-access analytics to all, delivers increased speed to deployment, provides leading security, compliance, and governance – with price performance for any organization. Whether organizations are seeking scalability in their enterprise data systems, advanced analytics capabilities (including the “big 4” and the “new 3”), real-time analytics (essential value-drivers from streaming data, including IoT, network logs, online customer interactions, supply chain, etc.), and the best in machine learning model-building and deployment services, Microsoft Azure Cloud has you covered. To learn more about it, go to https://azure.microsoft.com/en-us/solutions/cloud-scale-analytics and bring actionable business analytics to higher levels of proficiency and productivity across your organization.
I recently attended the Splunk .conf23 conference in Las Vegas. Well, the conference was in Vegas, while I was far away in my home office watching the live conference keynote sessions online. Despite the thousands of miles (and kilometers) of separation, I could feel the excitement in the room as numerous announcements were made, individuals were honored, customer success stories were presented, and new solutions and product features were revealed. I will summarize many of those here (specifically my major learning moments), though this report cannot provide a complete review of all that was said at .conf23, primarily because I attended only the two main keynote sessions, but also because the phenomenal number of remarkable things to hear and learn in those sessions exceeded my capacity to record them all in one succinct report.
When I reviewed highlights from last year’s Splunk .conf22 conference in my summary report at that time, I focused a lot on the Splunk Observability Cloud and its incredible suite of Observability and Monitoring products and services. This reflected my strong interest in observability at that time. My strong interest hasn’t diminished, and neither has Splunk’s developments and product releases in that space, as seen in observability’s prominent mention within many of Splunk’s announcements at this year’s .conf23 event. For a detailed report on the current state of observability this year, you can access and download “The State of Observability 2023” report from Splunk. Here are four specific metrics from the report, highlighting the potentially huge enterprise system benefits coming from implementing Splunk’s observability and monitoring products and services:
Four times as many leaders who implement observability strategies resolve unplanned downtime in just minutes, not hours or days.
Leaders report one-third the number of outages per year, on average, compared to those organizations who do not implement observability and monitoring.
Leaders are 7.9x as likely to say that their ROI on observability tools far exceeded expectations.
89% of leaders are completely confident in their ability to meet their application availability and performance requirements, versus just 43% of others.
Here are my top learnings from .conf23:
Splunk announced a new strategic partnership with Microsoft Azure, thereby adding another major cloud provider to their other cloud provider partnerships, bringing Splunk products and services into more enterprises through the Azure Marketplace. This partnership also specifically extends hybrid cloud capabilities that will enhance organizations’ digital resilience, while enabling transformation, modernization, migration, and growth in all enterprise digital systems with confidence, trust, and security.
Digital resilience was a major common theme across all of the Splunk announcements this week. As I heard someone say in the keynote session, “You had me at resilience!” By providing real-time data insights into all aspects of business and IT operations, Splunk’s comprehensive visibility and observability offerings enhance digital resilience across the full enterprise. Organizations are able to monitor integrity, quality drift, performance trends, real-time demand, SLA (service level agreement) compliance metrics, and anomalous behaviors (in devices, applications, and networks) to provide timely alerting, early warnings, and other confidence measures. From these data streams, real-time actionable insights can feed decision-making and risk mitigations at the moment of need. Such prescriptive capabilities can be more proactive, automated, and optimized, making digital resilience an objective fact for businesses, not just a business objective. I call that “digital resilience for the win!”
Several Splunk customer success stories were presented, with interesting details of their enterprise systems, the “back stories” that led them to Splunk, the transformations that have occurred since Splunk integration, and the metrics to back up the success stories. Customers presenting at .conf23 included FedEx, Carnival Corporation & plc, Inter IKEA, and VMware. Here are a few of the customer performance metrics presented (measuring performance changes following the Splunk integration into the customers’ enterprise systems): 3X Faster Response Time, 90% Faster Mean Time to Remediation, and 60X Faster Insights.
Splunk has brought greater integration and customer ease-of-use of their offerings through a Unified Security and Observability Platform. This unified operations center (Splunk Mission Control) amplifies the efficiency (time to problem resolution) and effectiveness (number of time-critical problems resolved) of ITOps and DevOps teams, requiring fewer manual steps in correlating data streams from multiple systems in order to determine the root cause of an incident. Further enhancing the user experience, the unified platform provides end-to-end enterprise systems visibility and federated search across those systems.
Splunk Mission Control (just mentioned above) – Splunk describes it best: “Splunk Mission Control brings together Splunk’s industry-leading security technologies that help customers take control of their detection, investigation and response processes. Splunk’s security offerings include security analytics (Splunk Enterprise Security), automation and orchestration (Splunk SOAR), and threat intelligence capabilities. In addition, Splunk Mission Control offers simplified security workflows with processes codified into response templates. With Splunk Mission Control, security teams can focus on mission-critical objectives, and adopt more proactive, nimble security operations.”
Model-Assisted Threat Hunts, also known as Splunk M-ATH, is Splunk’s brand name for machine learning-assisted threat hunting and mitigation. M-ATH is part of the PEAK (Prepare, Execute, and Act with Knowledge) Framework, that consists of three types of hunts: (1) Hypothesis-driven (i.e., testing for hypothesized threats, behaviors, and activities), (2) Baseline (i.e., search for deviations from normal behaviors through EDA: Exploratory Data Analysis), and (3) M-ATH (i.e., automation of the first two type of hunts, using AI and machine learning). M-ATH includes ML-assisted adaptive thresholding and outlier handling, for improved alerts (i.e., faster alerting with fewer false positives and false negatives).
“Don’t be a SOAR loser!” Okay, that’s what one of the Splunk speakers said at .conf23. By that, he was referring to being a winner with Splunk SOAR: Security Orchestration, Automation and Response. SOAR orchestrates, prioritizes, and automates security teams (SecOps) workflows and tasks, enabling more accurate, more complete, smarter, and faster response to security incidents. As Splunk says, “Automate so you can innovate.” Isn’t that always a business truth? If you can free your analyst teams to think outside the box, hypothesize, innovate, and test new methods and solutions, then that is the sure path to being a SAFE (Security Analytics For the Enterprise) winner: soar with SOAR! While SIEM (Security Information and Event Management) aims to manage the data flows, logging, audits, alerted events, and incident responses, SOAR automates these security activities (using machine learning and AI), monitors the data and events for anomalous behaviors, classifies (prioritizes) the events, and then orchestrates optimized security operations and incident responses (using playbooks).
Saving my best two .conf23 learning moments for last, first up is Splunk Edge Hub. This is a physical device, in the IoT (Internet of Things) family of sensors, that collects and streams data from the edge (i.e., from edge devices, cameras, streaming data sources, monitoring systems, and sensors of all types) into Splunk systems that go to work on those data: security operations, anomaly detection, event classification, trend detection, drift detection, behavior detection, and any other edge application that requires monitoring and observability, with an injection of machine learning and AI for intelligent data understanding, classification, prioritization, optimization, and automation. Since business thrives at the edge (through insights discovery and actionable analytics at the point—time and place—of data collection), an edge hub is just what a business needs to mitigate risk, ensure visibility, escalate incidents for review, optimize the operational response, and monitor the associated activities (causes and effects).
Splunk AI Assistant– Boom! This is the brilliant and innovative introduction of an AI assistant into Splunk products, services, and user workflows. This includes the latest and best of AI — generative AI and natural language interfaces integrated within the Splunk platform. This product release most definitely enables and “catalyzes digital resilience in cybersecurity and observability.” This is not just a product release. It is a “way of life” and “a way of doing business” with Splunk products and services. AI is not just a tacked-on feature, but it is a fundamental characteristic and property of those products’ features. Splunk AI increases productivity, efficiency, effectiveness, accuracy, completeness, reliability, and (yes!) resilience across all enterprise SecOps, ITOps, and AIOps functions, tasks, and workflows that are powered by Splunk. Generative AI enables the Splunk SecOps and ITOps tasks, workflows, processes, insights, alerts, and recommended actions to be domain-specific and customer-specific. It automatically detects anomalies and focuses attention where it’s needed most, for that business in that domain, while providing full control and transparency on which data and how data are used to train the AI, and how much control is assigned to the AI (by maintaining “human in the loop” functionality). With regard to the natural language features, Splunk AI Assistant leverages generative AI to provide an interactive chat experience and helps users create SPL (Splunk Processing Language) queries using natural language. This feature not only improves time-to-value, but it “helps make SPL more accessible, further democratizing an organization’s access to, and insights from, its data” – and that includes automated recommendations to the user for “next best action”, which is a great learning prompt for new Splunk users and SecOps beginners.
For a peek into my peak real-time experiences at .conf23, see my #splunkconf23 social thread on Twitter at https://bit.ly/3DjI5NU. Actually, go there and explore, because there is so much more to see there than I could cover in this one report.
Closing thoughts – AI (particularly generative AI) has been the hottest tech topic of the year, and Splunk .conf23 did not disappoint in their coverage of this topic. The agendas for some events are filled with generic descriptions that sing the praises of generative AI. This Splunk event .conf23 provided something far more beneficial and practical: they presented demonstrably valuable business applications of generative AI embedded in Splunk products, which deliver a convincing Splunk-specific productivity enhancer for new and existing users of Splunk products. When the tech hype train is moving as fast as it has been this year, it is hard for a business to quickly innovate, incorporate, and deliver substantially new features that use the new tech within their legacy products and services, but Splunk has done so, with top marks for those achievements.
Disclaimer: I was compensated as an independent freelance media influencer for my participation at the conference and for this article. The opinions expressed here are entirely my own and do not represent those of Splunk or of any Splunk partners. Any misrepresentations of the products and services mentioned in my statements are entirely my own responsibility. Nothing here should be construed as an offer to sell or as financial advice of any kind. My comments are entirely of a technical nature, focused on the technical capabilities of the items mentioned in the article.
Artificial intelligence (AI) is top of mind for executives, business leaders, investors, and most workplace employees everywhere. The impacts are expected to be large, deep, and wide across the enterprise, to have both short-term and long-term effects, to have significant potential to be a force both for good and for bad, and to be a continuing concern for all conscientious workers. In confronting these winds of change, enterprise leaders are faced with many new questions, decisions, and requirements – including the big question: are these winds of change helping us to move our organization forward (tailwinds) or are they sources of friction in our organization (headwinds)?
The current AI atmosphere in enterprises reminds us of the internet’s first big entrance into enterprises nearly three decades ago. I’m not referring to the early days of email and Usenet newsgroups, but the tidal wave of Web and e-Commerce applications that burst onto the business scene in the mid-to-late 1990’s. While those technologies brought much value to the enterprise, they also brought an avalanche of IT security concerns into the C-suite, leading to more authoritative roles for the CIO and the CISO. The fraction of enterprise budgets assigned to these IT functions (especially cybersecurity) suddenly and dramatically increased. That had and continues to have a very big and long-lasting impact.
The Web/e-Commerce tidal wave also brought a lot of hype and FOMO, which ultimately led to the Internet bubble burst (the dot-com crash) in the early 2000’s. AI, particularly the new wave of generative AI applications, has the potential to repeat this story, potentially unleashing a wave of similar patterns in the enterprise. Are we heading for another round of hype / high hopes / exhilaration / FOMO / crash and burn with AI? I hope not.
I would like to believe that a sound, rational, well justified, and strategic introduction of the new AI technologies (including ChatGPT and other generative AI applications) into enterprises can offer a better balance on the fast slopes of technological change (i.e., protecting enterprise leaders from getting out too far over their skis). In our earlier article, we discussed “AI Readiness is Not an Option.” In this article here, we offer some considerations for enterprise AI to add to those strategic conversations. Specifically, we look at considerations from the perspective of the fuel for enterprise AI applications: the algorithms, the data, and the enterprise AI infrastructure. Here is my list:
This year, artificial intelligence (AI) has become a major conversation centerpiece at home, in the park, at the gym, at work, everywhere. This is not entirely due to or related to ChatGPT and LLMs (large language models), though those have been the main drivers. The AI conversations, especially in technical circles, have focused intensively on generative AI, the creation of written content, images, videos, marketing copy, software code, speeches, and countless other things. For a short introduction to generative AI, see my article “Generative AI – Chapter 1, Page 1”.
While there has been huge public interest in generative AI (specifically, ChatGPT) by individuals, there has been a transformative impact on organizations everywhere, both in strategy conversations and tactical deployments. Businesses and others are seeking to leverage generative AI to increase productivity (efficiencies and effectiveness) in nearly all aspects of their enterprise.
To support essential enterprise AI strategy conversations, here are 12 key points for organizations to consider within the context of “AI readiness is not an option, but an imperative”:
Anyone who has been watching the AI space this year, even peripherally, will have noticed the flaming hot story of the year—ChatGPT and related chatbot applications. These AI applications are essentially deep machine learning models that are trained on hundreds of gigabytes of text and that can provide detailed, grammatically correct, and “mostly accurate” text responses to user inputs (questions, requests, or queries, which are called prompts). Specifically, these are LLMs—large language models. It is imperative, not an option, for organizations (and for most individuals) to be aware of what is going on here—not only because it is all over the news, but because it could affect your future self.
When I said “mostly accurate,” I meant that sometimes the ChatGPT responses go way off target—people refer to these as “hallucinations,” which is basically a reflection of the statistical basis of the models (see below)—the application will generate some plausible-sounding, grammatically correct statements that are complete falsehoods, such as “Leonardo da Vinci painted the Mona Lisa in 1815” (which is a real example of an observed ChatGPT hallucination).
I tested ChatGPT with my own account, and I was impressed with the results. I prompted it with various requests, including: Write a short story on a specific topic, provide a layperson’s explanations of some complex deep machine learning concepts, create a lesson plan to learn a tough subject, create an outline for a blog on a particular topic (no, not this one), and provide some financial advice on particular investments (no, it did not provide specific advice, but it did offer warnings like NFA “Not Financial Advice” and DYOR “Do Your Own Research”). You can find my results on my Medium blog site.
LLMs are so responsive and grammatically correct (even over many paragraphs of text) that some people worry that it is sentient. Guess what? It isn’t. It is merely a very large statistical model that provides the most likely sequence of words in response to a prompt. It is effectively a galaxy-sized statistically rich version of text autocomplete on your smartphone’s text messaging app, which already delivers some highly probable guesses for the missing words in a text message like this one: “Due to a client deadline, I will be working late at the ____ this ____, so I will be home late for ____.” LLMs can respond to much more complex (but well-posed) prompts, such as lesson plans for education, content for a business presentation, code for a software task, workflow steps for an IT project, and much more.
In order to help people to create well-posed prompts, the new discipline of prompt engineering has arisen. It’s not hard to find many online guides to prompt engineering, including guides for very specific industries, business tasks, workplace applications, and context-dependent scenarios. You don’t need prompt engineering to find those guides—a simple web search should do the trick. And guess what? When web search engines were first created, it took a while for us to learn how to submit well-posed keyword searches. That scenario is being played out again with ChatGPT and prompt engineering, but now our queries are aimed at a much more language-based, AI-powered, statistically rich application. If you understand Bayes’ Theorem and Bayesian statistics, then you will understand me when I say that we are talking here about an enormously more enriched set of priors, likelihoods, and evidence to feed the LLMs—so, it should not be surprising that the posteriors are shockingly good for large text outputs (most of the time).
LLMs are a subset of the deep learning field of natural language processing (NLP), which includes natural language understanding (NLU) and natural language generation (NLG). Think of chatbots and you get the idea, just expanded to a much, much larger domain of AI-based conversation.
Computer vision (CV) is another subset of deep learning, specifically aimed at object/pattern detection, recognition, and classification in images (including still images and video sequences). ChatGPT and LLMs are examples of generative AI using NLP for text generation. Stable Diffusion, Midjourney, and Dall-E are examples of generative AI using CV for image generation. Oh, by the way, I asked the generative AI at Stable Diffusion to create some images to go with my short story (which you can find on my Medium blog).
Beyond the individual examples of generative AI (and its components, ChatGPT, Stable Diffusion, etc.) that we can all experiment with, the applications in the enterprise can be tremendously impactful and transformative for organizations and the future of work. Those next chapters in the story are being written right now.
Continue reading about Enterprise AI in these posts:
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. The insights are used to produce informative content for stakeholders (decision-makers, business users, and clients). Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data.
We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry. With all the data in and around the enterprise, users would say that they have a lot of information but need more insights to assist them in producing better and more informative content. This is where we dispel an old “big data” notion (heard a decade ago) that was expressed like this: “we need our data to run at the speed of business.” Instead, what we really need is for our business to run at the speed of data. It is a major digital transformation challenge for businesses to keep up with data flows coming from a multitude of diverse sources, in different formats, at different cadences, on different dimensions of the enterprise, captured “safely” in different business silos. Transforming data to actionable insights and informative content needs some help!
AI is now helping in all these steps – not simply because it is “Artificial” intelligence, but primarily because AI is a tool for assisted, amplified, and augmented intelligence (the “new AI”) and because AI powers accelerated and automated intelligence, in order to deliver actionable intelligence. It appears that it’s AI everywhere all the time.
AI can help business users extract and produce (i.e., generate) informative content from insights. Plus, AI can also help find key insights encoded in data. And AI can help users find the appropriate data that they need from across the enterprise. In the language of Information Retrieval, AI delivers both high Recall (“did I get all the data that I need?”) and high Precision (“did I get only the data that I need?).
Discover the essential data – that’s AI.
Extract the essential insights from the data – that’s AI.
Produce essential content from the insights – that’s AI.
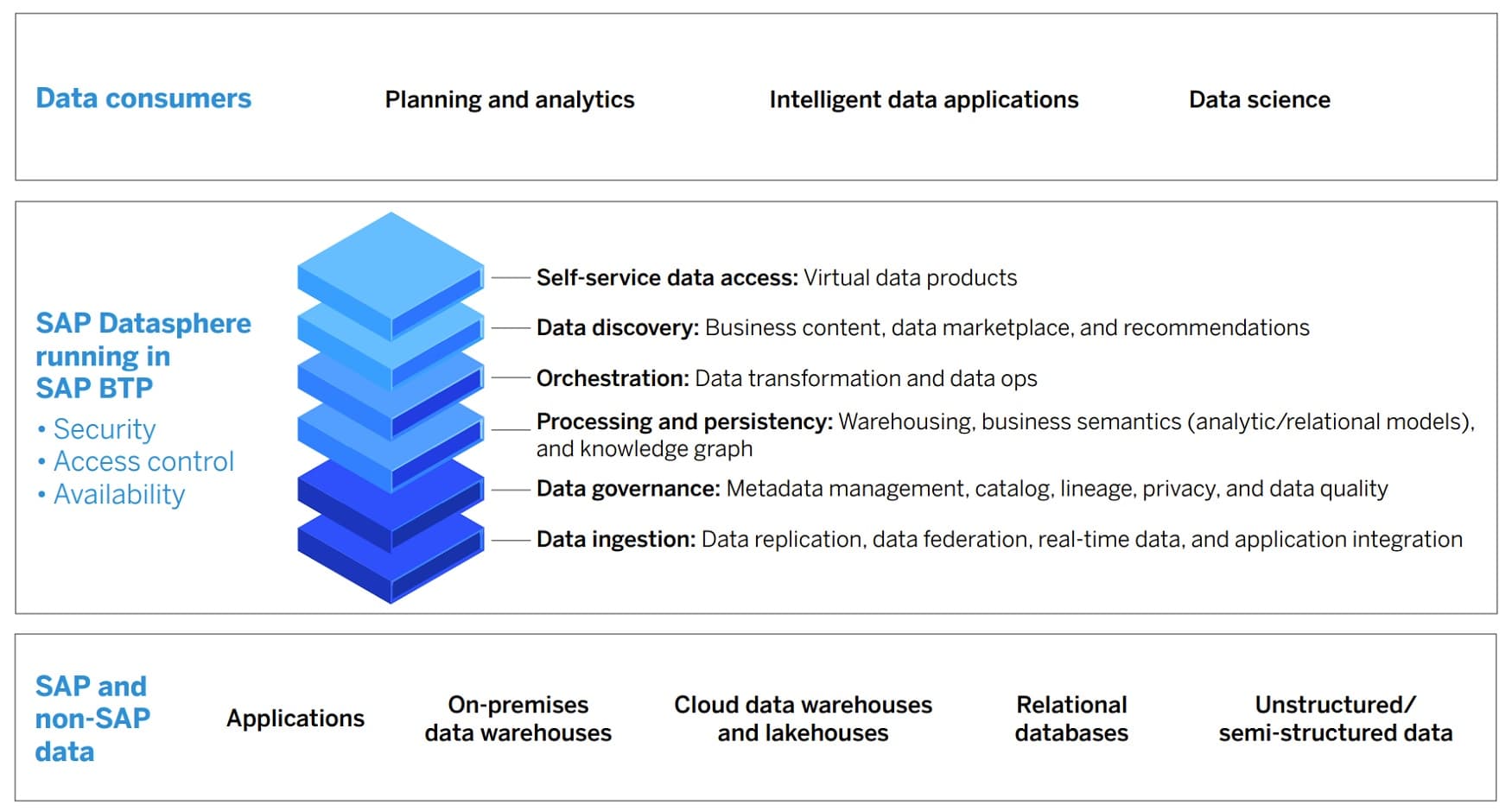
Well, okay, we can slap the “AI” label on everything, but what good is that? How are we helped when we board the AI hype train? In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies and business domain expertise at each step. This is where SAP Datasphere (the next generation of SAP Data Warehouse Cloud) comes in.
The new SAP Datasphere comprehensive data service provides powerful, seamless, and scalable access across the enterprise, across business departments, and across business silos to the specific mission-critical business data collection(s) that are needed for each unique business use case: access to external insights from data on the marketplace and competitors, access to internal insights from data on business processes and enterprise resources, and access to insights on customer-facing business products and services at the intersection of internal and external data sources.
So, if your business users don’t have access to the right data in the right context at the right time for the right business questions, then the whole business data workflow breaks down. SAP Datasphere has arrived to address those pain points, by enabling discovery, access, and integration of the heterogeneous data distributed across the enterprise. And so begins the process of insight discovery and content creation that meets the most significant, timely, and case-specific needs of decision-makers, business knowledge workers, and other stakeholders.
The release of SAP Datasphere was launched and announced globally on March 8, 2023. Live online presentations, demos, and customer testimonials were complemented with new content posted at sap.com/datasphere. Here are just 10 of the many key features of Datasphere that were covered during the launch day announcements:
Datasphere works with the SAP Analytics Cloud and runs on the existing SAP BTP (Business Technology Platform), with all the essential features: security, access control, high availability.
Datasphere accesses and integrates both SAP and non-SAP data sources into end-users’ data flows, including on-prem data warehouses, cloud data warehouses and lakehouses, relational databases, virtual data products, in-memory data, and applications that generate data (such as external API data loads).
Datasphere manages and integrates structured, semi-structured, and unstructured data types.
Datasphere empowers data democratization, by providing all business users with self-service data access, including virtual data products that can be stored, re-used, and shared.
Datasphere is a data discovery tool with essential functionalities: recommendations, data marketplace, and business content (i.e., incorporates the business context of the data and data products that are being recommended and delivered).
Datasphere goes beyond the “big three” data usage end-user requirements (ease of discovery, access, and delivery) to include data orchestration (data ops and data transformations) and business data contextualization (semantics, metadata, catalog services).
Datasphere is an enhanced data warehousing service that includes business semantics (through both analytic and relational models) and a knowledge graph (linking business content with business context).
Datasphere provides full-spectrum data governance: metadata management, data catalogs, data privacy, data quality, and data lineage (provenance) tracking.
Datasphere provides all the outgoing data orchestration functions and incoming data ingestion functions, including replication, federation, real-time stream processing, and application integration.
Datasphere is not just for data managers. It thrives with data consumers, who are doing planning, analytics, data science, and developing intelligent data applications – by providing those users with an end-to-end view of their data landscape in a trusted, secure, and actionable data environment.
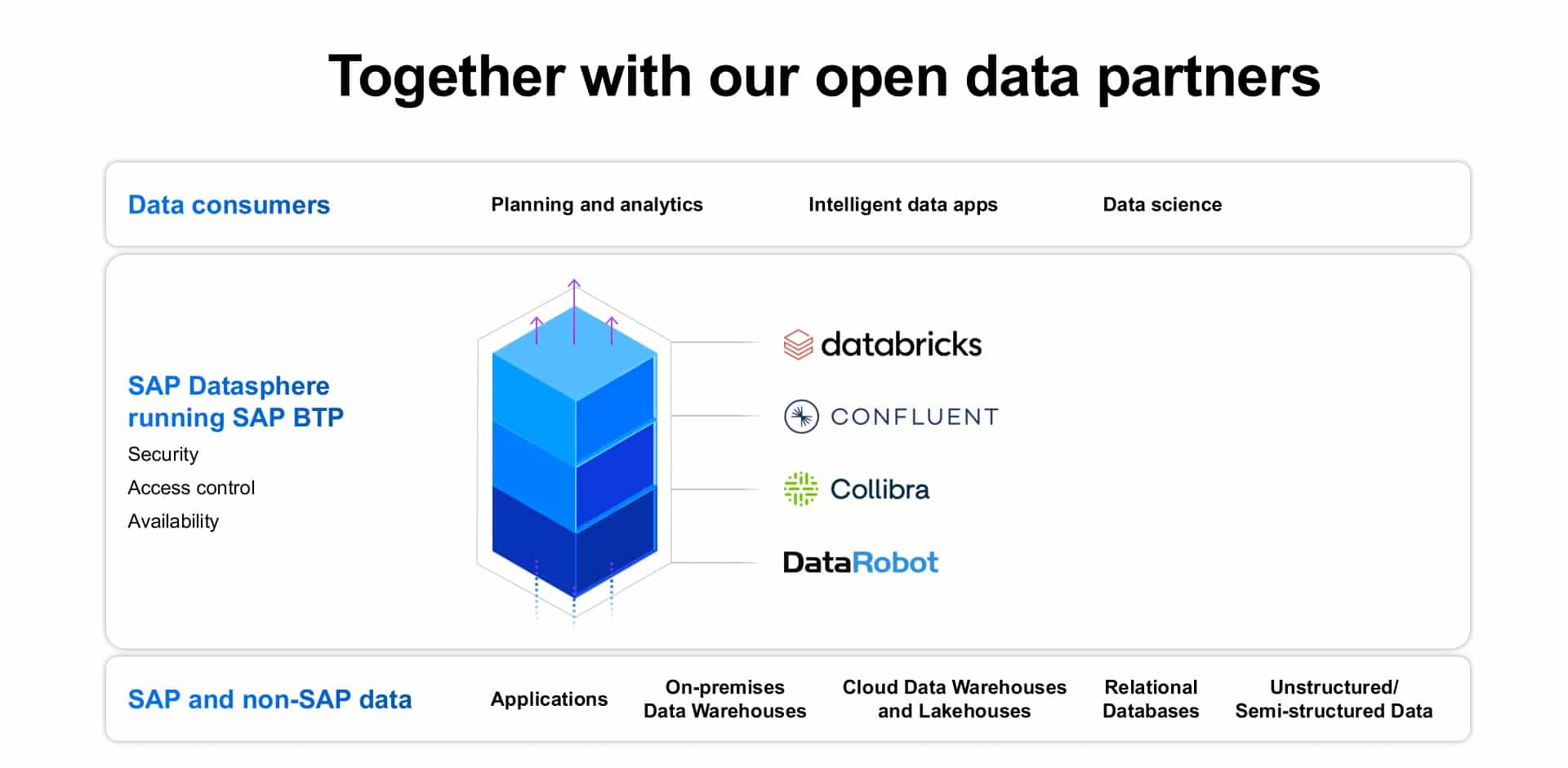
SAP also announced key partners that further enhance Datasphere as a powerful business data fabric. These partners are:
Collibra – providing data governance and discovery (metadata, catalogs) across the entire data landscape.
Confluent – providing access and discovery across real-time event data and streaming data. This emphatically addresses the “data in motion” challenge of enabling “business to run at the speed of data.”
Databricks – providing the complete business context across the evolved Data Warehouse Cloud – the new Data Lakehouse platform.
DataRobot – provides the AI, machine learning (ML), and AutoML capabilities that address the augmented intelligence requirements described at the beginning of this article.
I will finish with three quotes. The first is SAP customer testimonial from Mr. David Johnston, the Chief Information Officer at Messer Americas (leading provider of industrial and medical gases for over 120 years):
“The [Datasphere] business data fabric architecture enables us to bring SAP and non-SAP data together in the seamless and self-service way we’ve been envisioning. SAP Datasphere provided us with a solution to build a harmonized layer, or business data fabric, across SAP and non-SAP, cloud or on-premise data sources, making the best use of our existing investments [in both SAP and non-SAP data services].”
The second quote is from independent analyst Tony Baer:
“SAP’s goal is not simply pairing a data transformation factory with a data warehouse, but instead delivering a service that preserves the context of source data. As you would guess, maintaining context relies on metadata. The challenge is that when you use existing tools for replicating, moving and transforming data, the metadata typically does not usually go along with it. … SAP’s applications are a rich treasure store for business data and the process semantics that go with them. So, it’s logical that SAP has expanded on the business semantic layer of its Data Warehouse Cloud to deliver a data fabric that surfaces the metadata in business terms.”
The third quote is from Juergen Mueller, SAP Chief Technology Officer and member of the Executive Board of SAP SE:
“With SAP customers generating 87% of total global commerce, SAP data is among a company’s most valuable business assets and is contained in the most important functions of an organization, from manufacturing to supply chains, finance, human resources and more. We want to help our customers take the next step to easily and confidently integrate SAP data with non-SAP data from third-party applications and platforms, unlocking entirely new insights and knowledge to bring digital transformation to another level.”
Read, take a tour, try the free tier, deep dive, and learn more about SAP Datasphere here:
Generative AI is the biggest and hottest trend in AI (Artificial Intelligence) at the start of 2023. While generative AI has been around for several years, the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities.
Every business wants to get on board with ChatGPT, to implement it, operationalize it, and capitalize on it. It is important to realize that the usual “hype cycle” rules prevail in such cases as this. First, don’t do something just because everyone else is doing it – there needs to be a valid business reason for your organization to be doing it, at the very least because you will need to explain it objectively to your stakeholders (employees, investors, clients). Second, doing something new (especially something “big” and disruptive) must align with your business objectives – otherwise, you may be steering your business into deep uncharted waters that you haven’t the resources and talent to navigate. Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy.
I suggest that the simplest business strategy starts with answering three basic questions: What? So what? Now what? That is: (1) What is it you want to do and where does it fit within the context of your organization? (2) Why should your organization be doing it and why should your people commit to it? (3) How do we get started, when, who will be involved, and what are the targeted benefits, results, outcomes, and consequences (including risks)? In short, you must be willing and able to answer the six WWWWWH questions (Who? What? When? Where? Why? and How?).
Another strategy perspective on technology-induced business disruption (including generative AI and ChatGPT deployments) is to consider the three F’s that affect (and can potentially derail) such projects. Those F’s are: Fragility, Friction, and FUD (Fear, Uncertainty, Doubt).
Fragility occurs when a built system is easily “broken” when some component is changed. These changes may include requirements drift, data drift, model drift, or concept drift. The first one (requirements drift) is a challenge in any development project (when the desired outcomes are changed, sometimes without notifying the development team), but the latter three are more apropos to data-intensive product development activities (which certainly describes AI projects). A system should be sufficiently agile and modular such that changes can be made with as little impact to the overall system design and operations as possible, thus keeping the project off the pathway to failure. Since ChatGPT is built from large language models that are trained against massive data sets (mostly business documents, internal text repositories, and similar resources) within your organization, consequently attention must be given to the stability, accessibility, and reliability of those resources.
Friction occurs when there is resistance to change or to success somewhere in the project lifecycle or management chain. This can be overcome with small victories (MVP minimum viable products, or MLP minimum lovable products) and with instilling (i.e., encouraging and rewarding) a culture of experimentation across the organization. When people are encouraged to experiment, where small failures are acceptable (i.e., there can be objective assessments of failure, lessons learned, and subsequent improvements), then friction can be minimized, failure can be alleviated, and innovation can flourish. A business-disruptive ChatGPT implementation definitely fits into this category: focus first on the MVP or MLP.
FUD occurs when there is too much hype and “management speak” in the discussions. FUD can open a pathway to failure wherever there is: (a) Fear that the organization’s data-intensive, machine learning, AI, and ChatGPT activities are driven by FOMO (fear of missing out, sparked by concerns that your competitors are outpacing your business); (b) Uncertainty in what the AI / ChatGPT advocates are talking about (a “Data Literacy” or “AI Literacy” challenge); or (c) Doubt that there is real value in the disruptive technology activities (due to a lack of quick-win MVP or MLP examples).
I have developed a few rules to help drive quick wins and facilitate success in data-intensive and AI (e.g., Generative AI and ChatGPT) deployments. These rules are not necessarily “Rocket Science” (despite the name of this blog site), but they are common business sense for most business-disruptive technology implementations in enterprises. Most of these rules focus on the data, since data is ultimately the fuel, the input, the objective evidence, and the source of informative signals that are fed into all data science, analytics, machine learning, and AI models.
Here are my 10 rules (i.e., Business Strategies for Deploying Disruptive Data-Intensive, AI, and ChatGPT Implementations):
Honor business value above all other goals.
Begin with the end in mind: goal-oriented, mission-focused, and outcomes-driven, while being data-informed and technology-enabled.
Know thy data: understand what it is (formats, types, sampling, who, what, when, where, why), encourage the use of data across the enterprise, and enrich your datasets with searchable (semantic and content-based) metadata (labels, annotations, tags). The latter is essential for AI implementations.
Love thy data: data are never perfect, but all the data may produce value, though not immediately. Clean it, annotate it, catalog it, and bring it into the data family (connect the dots and see what happens). For example, outliers are often dismissed as random fluctuations in data, but they may be signaling at least one of these three different types of discovery: (a) data quality problems, associated with errors in the data measurement and capture processes; (b) data processing problems, associated with errors in the data pipeline and transformation processes; or (c) surprise discovery, associated with real previously unseen novel events, behaviors, or entities arising in your data stream.
Do not covet thy data’s correlations: a random six-sigma event is one-in-a-million. So, if you have 1 trillion data points (e.g., a Terabyte of data), then there may be one million such “random events” that will tempt any decision-maker into ascribing too much significance to this natural randomness.
Validation is a virtue, but generalization is vital: a model may work well once, but not on the next batch of data. We must monitor for overfitting (fitting the natural variance in the data), underfitting (bias), data drift, and model drift. Over-specifying and over-engineering a model for a data-intensive implementation will likely not be applicable to previously unseen data or for new circumstances in which the model will be deployed. A lack of generalization is a big source of fragility and dilutes the business value of the effort.
Honor thy data-intensive technology’s “easy buttons” that enable data-to-discovery (D2D), data-to-“informed decision” (D2ID), data-to-“next best action” (D2NBA), and data-to-value (D2V). These “easy buttons” are: Pattern Detection (D2D), Pattern Recognition (D2ID), Pattern Exploration (D2NBA), and Pattern Exploitation (D2V).
Remember to Keep it Simple and Smart (the “KISS” principle). Create a library of composable, reusable building blocks and atomic business logic components for integration within various generative AI implementations: microservices, APIs, cloud-based functions-as-a-service (FaaS), and flexible user interfaces. (Suggestion: take a look at MACH architecture.)
Keep it agile, with short design, develop, test, release, and feedback cycles: keep it lean, and build on incremental changes. Test early and often. Expect continuous improvement. Encourage and reward a Culture of Experimentation that learns from failure, such as “Test, or get fired!”
Finally, I offer a very similar (shorter and slightly different) set of Business Strategies for Deploying Disruptive Data-Intensive, AI, and ChatGPT Implementations, from the article “The breakthrough that is ChatGPT: How much does it cost to build?“. Here is the list from that article’s “C-Suite’s Guide to Developing a Successful AI Chatbot”:
I recently attended (virtually) CX Summit 2021, presented by Five9, which focused on “CX Reimagined.” At first this title for the event seemed a bit grandiose to me – Reimagined! After attending the event, I now think the title was perfect, and it could have gone even further. I saw how the “art of the possible” in CX (Customer Experience) and EX (Employee Experience) in the Contact Center is already being realized and is being taken to new realms of possibility through AI and Cloud empowerments.
The evolved (reimagined) Contact Center now comes with more options for digital channels to accommodate the customer, more voice data-powered services that serve both the customer and the contact center representative, and more seamless actions on both ends of the call line, even for complex inquiries. This is all enabled by the 3 A’s: AI, Automation, and voice Analytics. We have heard it before: “happy employee, happy customer!” That now looks like this: “EX is the new CX.” Boom!
In an information-packed talk from Gartner Analyst Drew Kraus on “Getting Past the Hype in Customer Service”, where he reviewed just how much hype there is in the customer service and support technologies market, it became clear to me that Five9 delivers on the needs, not the hype.
Another informative and data-packed presentation was by Five9 SVP Scott Kolman and COMMfusion analyst Blair Pleasant, where they presented and did a deep dive into the Five9 survey “2021 Customer Service Index – Learn how customers have reimagined the customer service experience.” I won’t go too deep here (you should watch the whole session on-demand). Some interesting highlights include:
Five9 surveyed 2048 consumers, with participants from 7 countries, representing ages 19 to early 70’s. They also completed a similar survey in 2020. Side-by-side comparisons of the survey results (by age, by year of survey, and by country) for the different survey questions were quite informative and potentially quite useful for any contact center operation. If that’s what you or your business does, then you should investigate these “Voice of the Customer” results.
Across all demographics, only 25% of respondents felt that their contact center experience got worse (either “much worse” or “slightly worse”) from 2020 to 2021. We might have expected a different result with the pandemic raging. Everyone else (75%) felt that their experience got better, much better, or had no opinion.
Some very surprising results appeared (with significant differences between countries) when people were asked to rate the keys to “Good Service Experience”. Highly rated categories were “Rep gets right answer, even if it takes more time” (33%); “Rep can answer my question quickly’’ (26%); and “Don’t have to wait long to reach rep” (20%).
Similarly, there were some significant differences by country when people were asked to rate the keys to “Bad Service Experience”. Top responses included: “Get passed from one rep to another” (34%); “Have to wait long to reach rep” (26%); and a tie for third place (at 13%) for “Cue/on hold system not helpful” and “Rep cannot answer my question quickly”. (Remember, that despite these seriously bad experiences, only 25% of respondents generally saw a drop in customer service experience in the past year.)
One of the more enlightening survey results appeared when asked, “How likely are you to do business with a company if you have a Poor Service Experience?” The USA responses were significantly different than responses from the other 6 countries in the survey in one category: over 11% of USA respondents were “very likely” to continue doing business, versus 3-6% of non-USA respondents being “very likely”. However, in the “somewhat likely” category, all countries were in the range 10-16%, with the USA respondents close to the midpoint, near 14%. In my opinion (not expressed by the session presenters), a reason for these seemingly incompatible responses is that there are two sentiments being conflated in this one question. On the one hand, you have the bad experience on “this” call. On the other hand, you have perhaps the much worse (time-consuming) future experience of switching providers and dealing with the corresponding onboarding (for whatever service this is about). I might be “somewhat likely” to switch providers after one bad call experience, but I would not be “very likely” to go through the pain of switching providers and all that entails.
There were many interesting and powerful sessions in addition to this one, which I focused on here because it presented lots of survey data, and I love data! Another great session was the presentation by former astronaut (now Professor) Michael Massimino – brilliant and inspiring, with numerous words of wisdom, leadership advice, and life’s lessons learned. Of course, I admit that I was drawn into his NASA space stories, including the Hubble Telescope repair mission that almost went wrong, because I worked with the Hubble Space Telescope project for 10 years and I worked an additional 10 years at NASA’s Goddard Space Flight Center where many of the telescope’s instruments were tested.
My big takeaway from the Five9 CX Summit is how cloud, AI, automation, and voice analytics are rapidly driving change in the positive direction for contact center representatives and for customers who call in. Maybe that’s why the customer experience didn’t change much from 2020 to 2021, because a lot of those technologies have already been deployed in the past couple of years, particularly for Five9’s clients.
Chatbots and conversational AI are just part of the story – there’s so much more. Five9’s new cloud-enabled, AI-powered, voice data-driven solutions and services described at the summit are definitely worth exploring and investigating for your contact center: IVA (Intelligent Virtual Agents), VoiceStream, Agent Assist, Studio7, Practical AI, WFO (Work Flow Optimization), Conversation Architect, and UC (unified communications) integration into the contact center VX (Voice Experience) workflow.
Learn more about CX Reimagined and the roles of AI, Automation, Cloud, Voice Analytics, and Omnichannel Customer Engagement in the modern contact center at CX Summit 2021, presented by Five9. (Even if you missed the live event, the sessions are recorded, so you can watch them on-demand at any time you wish.) See for yourself where the Reimagined becomes the Realized in CX. And learn why EX is the new CX.
Note: This article was sponsored. The opinions expressed here are my own and do not represent the opinions of any other person, company, or entity.