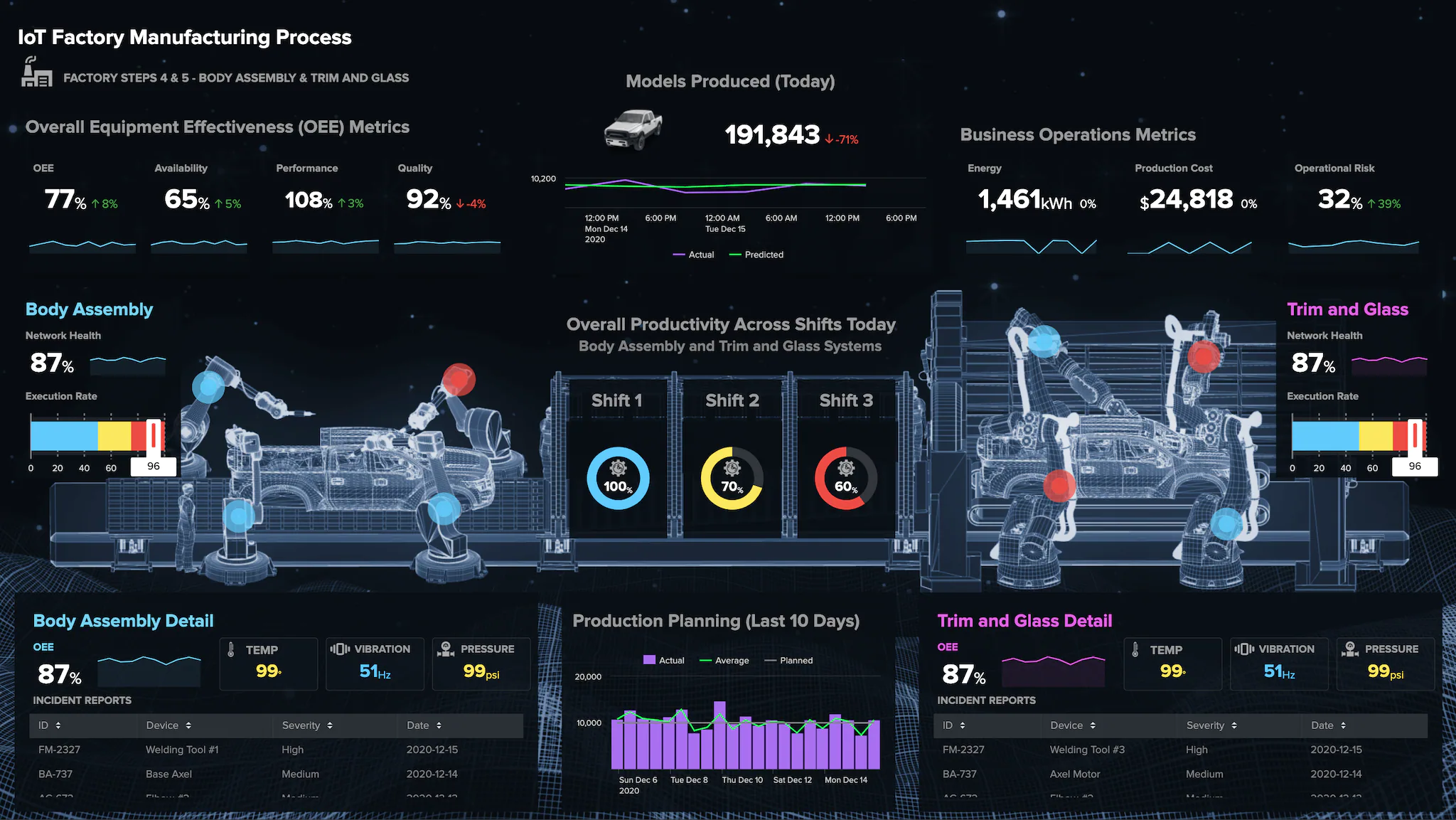
I recently attended the Splunk .conf22 conference. While the event was live in-person in Las Vegas, I attended virtually from my home office. Consequently I missed the incredible in-person experience of the brilliant speakers on the main stage, the technodazzle of 100’s of exhibitors’ offerings in the exhibit arena, and the smooth hip hop sounds from the special guest entertainer — guess who?
What I missed in-person was more than compensated for by the incredible online presentations by Splunk leaders, developers, and customers. If you have ever attended a major expo at one of the major Vegas hotels, you know that there is a lot of walking between different sessions — literally, miles of walking per day. That’s good for you, but it often means that you don’t attend all of the sessions that you would like because of the requisite rushing from venue to venue. None of that was necessary on the Splunk .conf22 virtual conference platform. I was able to see a lot, learn a lot, be impressed a lot, and ponder a lot about all of the wonderful features, functionalities, and future plans for the Splunk platform.
One of the first major attractions for me to attend this event is found in the primary descriptor of the Splunk Platform — it is appropriately called the Splunk Observability Cloud, which includes an impressive suite of Observability and Monitoring products and services. I have written and spoken frequently and passionately about Observability in the past couple of years. For example, I wrote this in 2021:
“Observability emerged as one of the hottest and (for me) most exciting developments of the year. Do not confuse observability with monitoring (specifically, with IT monitoring). The key difference is this: monitoring is what you do, and observability is why you do it. Observability is a business strategy: what you monitor, why you monitor it, what you intend to learn from it, how it will be used, and how it will contribute to business objectives and mission success. But the power, value, and imperative of observability does not stop there. Observability meets AI – it is part of the complete AIOps package: ‘keeping an eye on the AI.’ Observability delivers actionable insights, context-enriched data sets, early warning alert generation, root cause visibility, active performance monitoring, predictive and prescriptive incident management, real-time operational deviation detection (6-Sigma never had it so good!), tight coupling of cyber-physical systems, digital twinning of almost anything in the enterprise, and more. And the goodness doesn’t stop there.”
The dominant references everywhere to Observability was just the start of awesome brain food offered at Splunk’s .conf22 event. Here is a list of my top moments, learnings, and musings from this year’s Splunk .conf:
Observability for Unified Security with AI (Artificial Intelligence) and Machine Learning on the Splunk platform empowers enterprises to operationalize data for use-case-specific functionality across shared datasets. (Reference)
The latest updates to the Splunk platform address the complexities of multi-cloud and hybrid environments, enabling cybersecurity and network big data functions (e.g., log analytics and anomaly detection) across distributed data sources and diverse enterprise IT infrastructure resources. (Reference)
Splunk Enterprise 9.0 is here, now! Explore and test-drive it (with a free trial) here.
The new Splunk Enterprise 9.0 release enables DevSecOps users to gain more insights from Observability data with Federated Search, with the ability to correlate ops with security alerts, and with Edge Management, all in one platform. (Reference)
Security information and event management (SIEM) on the Splunk platform is enhanced with end-to-end visibility and platform extensibility, with machine learning and automation (AIOps), with risk-based alerting, and with Federated Search (i.e., Observability on-demand). (Reference)
Customer success story: As a customer-obsessed bank with ultra-rapid growth, Nubank turned to Splunk to optimize data flows, analytics applications, customer support functions, and insights-obsessed IT monitoring. (Reference)
The key characteristics of the Splunk Observability Cloud are Resilience, Security, Scalability, and EXTENSIBILITY. The latter specifically refers to the ease in which developers can extend Splunk’s capabilities to other apps, applying their AIOps and DevSecOps best practices and principles! Developers can start here.
The Splunk Observability Cloud has many functions for data-intensive IT, Security, and Network operations, including Anomaly Detection Service, Federated Search, Synthetic Monitoring, Incident Intelligence, and much more. Synthetic monitoring is essentially digital twinning of your network and IT environment, providing insights through simulated risks, attacks, and anomalies via predictive and prescriptive modeling. [Reference]
Splunk Observability Cloud’s Federated Search capability activates search and analytics regardless of where your data lives — on-site, in the cloud, or from a third party. (Reference)
The new release of the Splunk Data Manager provides a simple, modern, automated experience of data ingest for Splunk Cloud admins, which reduces the time it takes to configure data collection (from hours/days to minutes). (Reference)
Splunk works on data, data, data, but the focus is always on customer, customer, customer — because delivering best outcomes for customers is job #1. Explore Splunk’s amazing Partner ecosystem (Partnerverse) and the impressive catalog of partners’ solutions here.
In summary, here is my list of key words and topics that illustrate the diverse capabilities and value-packed features of the Splunk Observability Cloud Platform that I learned about at the .conf22 event:
– Anomaly Detection Assistant – Risk-based Alerting (powered by AI and Machine Learning scoring algorithms) – Federated Search (Observability on-demand) – End-to-End Visibility – Platform Extensibility – Massive(!) Scalability of the Splunk Observability Cloud (to billions of transactions per day) – Insights-obsessed Monitoring (“We don’t need more information. We need more insights.”) – APIs in Action (to Turn Data into Doing™) – Splunk Incident Intelligence – Synthetic Monitoring (Digital Twin of Network/IT infrastructure) – Splunk Data Manager – The Splunk Partner Universe (Partnerverse)
My closing thought — Cybersecurity is basically Data Analytics: detection, prediction, prescription, and optimizing for unpredictability. This is what Splunk lives for!
Disclaimer: I was compensated as an independent freelance media influencer for my participation at the conference and for this article. The opinions expressed here are entirely my own and do not represent those of Splunk or of any Splunk partners. Any misrepresentations of the products and services mentioned in my statements are entirely my own responsibility. Nothing here should be construed as an offer to sell or as financial advice of any kind. My comments are entirely of a technical nature, focused on the technical capabilities of the items mentioned in the article.
In this post, we will examine ways that your organization can separate useful content into separate categories that amplify your own staff’s performance. Before we start, I have a few questions for you.
What
attributes of your organization’s strategies can you attribute to successful
outcomes? How long do you deliberate before taking specific deliberate actions?
Do you converse with your employees about decisions that might be the converse
of what they would expect? Is a process modification that saves a minute in
someone’s workday considered too minute for consideration? Do you present your
employees with a present for their innovative ideas? Do you perfect your plans
in anticipation of perfect outcomes? Or do you project foregone conclusions on
a project before it is completed?
If
you have good answers to these questions, that is awesome! I would not contest
any of your answers since this is not a contest. In fact, this is actually
something quite different. Before you combine all these questions in a heap and
thresh them in a combine, and before you buffet me with a buffet of skeptical
remarks, stick with me and let me explain. Do not close the door on me when I
am so close to giving you an explanation.
What
you have just experienced is a plethora of heteronyms. Heteronyms are words
that are spelled identically but have different meanings when pronounced
differently. If you include the title of this blog, you were just presented
with 13 examples of heteronyms in the preceding paragraphs. Can you find them
all?
Seriously
now, what do these word games have to do with content strategy? I would say
that they have a great deal to do with it. Specifically, in the modern era of
massive data collections and exploding content repositories, we can no longer
simply rely on keyword searches to be sufficient. In the case of a heteronym, a
keyword search would return both uses of the word, even though their meanings
are quite different. In “information retrieval” language, we would say that we
have high RECALL, but low PRECISION. In other words, we can find most occurrences
of the word (recall), but not all the results correspond to the meaning of our
search (precision). That is no longer good enough when the volume is so high.
The
key to success is to start enhancing and augmenting content management systems
(CMS) with additional features: semantic content and context. This is
accomplished through tags, annotations, and metadata (TAM). TAM management,
like content management, begins with business strategy.
Strategic content management focusses on business outcomes, business process improvement, efficiency (precision – i.e., “did I find only the content that I need without a lot of noise?”), and effectiveness (recall – i.e., “did I find all the content that I need?”). Just because people can request a needle in the haystack, it is not a good thing to deliver the whole haystack that contains that needle. Clearly, such a content delivery system is not good for business productivity. So, there must be a strategy regarding who, what, when, where, why, and how is the organization’s content to be indexed, stored, accessed, delivered, used, and documented. The content strategy should emulate a digital library strategy. Labeling, indexing, ease of discovery, and ease of access are essential if end-users are to find and benefit from the collection.
My favorite approach to TAM creation and to modern data management in general is AI and machine learning (ML). That is, use AI and machine learning techniques on digital content (databases, documents, images, videos, press releases, forms, web content, social network posts, etc.) to infer topics, trends, sentiment, context, content, named entity identification, numerical content extraction (including the units on those numbers), and negations. Do not forget the negations. A document that states “this form should not be used for XYZ” is exactly the opposite of a document that states “this form must be used for XYZ”. Similarly, a social media post that states “Yes. I believe that this product is good” is quite different from a post that states “Yeah, sure. I believe that this product is good. LOL.”
Contextual TAM enhances a CMS with knowledge-driven search and retrieval, not just keyword-driven. Contextual TAM includes semantic TAM, taxonomic indexing, and even usage-based tags (digital breadcrumbs of the users of specific pieces of content, including the key words and phrases that people used to describe the content in their own reports). Adding these to your organization’s content makes the CMS semantically searchable and usable. That’s far more laser-focused (high-precision) than keyword search.
One
type of implementation of a content strategy that is specific to data
collections are data catalogs. Data catalogs are very useful and important.
They become even more useful and valuable if they include granular search
capabilities. For example, the end-user may only need the piece of the dataset
that has the content that their task requires, versus being delivered the full
dataset. Tagging and annotating those subcomponents and subsets (i.e.,
granules) of the data collection for fast search, access, and retrieval is also
important for efficient orchestration and delivery of the data that fuels AI,
automation, and machine learning operations.
One
way to describe this is “smart content” for intelligent digital business
operations. Smart content includes labeled (tagged, annotated) metadata (TAM).
These labels include content, context, uses, sources, and characterizations
(patterns, features) associated with the whole content and with individual
content granules. Labels can be learned through machine learning, or applied by
human experts, or proposed by non-experts when those labels represent cognitive
human-discovered patterns and features in the data. Labels can be learned and
applied in existing CMS, in massive streaming data, and in sensor data
(collected in devices at the “edge”).
Some specific tools and techniques that can be applied to CMS to generate smart content include these:
Natural language understanding and natural language generation
Topic modeling (including topic drift and topic emergence detection)
Consequently, smart content thrives at the convergence of AI and content. Labels are curated and stored with the content, thus enabling curation, cataloguing (indexing), search, delivery, orchestration, and use of content and data in AI applications, including knowledge-driven decision-making and autonomous operations. Techniques that both enable (contribute to) and benefit from smart content are content discovery, machine learning, knowledge graphs, semantic linked data, semantic data integration, knowledge discovery, and knowledge management. Smart content thus meets the needs for digital business operations and autonomous (AI and intelligent automation) activities, which must devour streams of content and data – not just any content, but smart content – the right (semantically identified) content delivered at the right time in the right context.
The
four tactical steps in a smart content strategy include:
Characterize and contextualize the patterns, events, and entities in the content collection with semantic (contextual) tags, annotation, and metadata (TAM).
Collect, curate, and catalog (i.e., index) each TAM component to make it searchable, accessible, and reusable.
Deliver the right content at the right time in the right context to the decision agent.
Decide and act on the delivered insights and knowledge.
Remember,
do not be content with your current content management strategy. But discover
and deliver the perfect smart content that perfects your digital business outcomes.
Smart content strategy can save end-users countless minutes in a typical
workday, and that type of business process improvement certainly is not too
minute for consideration.
The year 2020 was remarkably different in many
ways from previous years. In at least one way, it was not different, and that was
in the continued development of innovations that are inspired by data. This
steady march of data-driven innovation has been a consistent characteristic of
each year for at least the past decade. These data-fueled innovations come in
the form of new algorithms, new technologies, new applications, new concepts,
and even some “old things made new again”.
I provide below my perspective on what was
interesting, innovative, and influential in my watch list of the Top 10 data
innovation trends during 2020.
1) Automated Narrative Text Generation
tools became incredibly good in 2020, being able to create scary good “deep
fake” articles. The GPT-3 (Generative Pretrained Transformer, 3rd generation
text autocomplete) algorithm made headlines since it demonstrated that it can
start with a very thin amount of input (a short topic description, or a question),
from which it can then generate several paragraphs of narrative that are very
hard (perhaps impossible) to distinguish from human-generated text. However, it
is far from perfect, since it certainly does not have reasoning skills, and it
also loses its “train of thought” after several paragraphs (e.g., by making
contradictory statements at different places in the narrative, even though the
statements are nicely formed sentences).
2) MLOps became the expected norm
in machine learning and data science projects. MLOps takes the
modeling, algorithms, and data wrangling out of the experimental “one off”
phase and moves the best models into deployment and sustained operational phase.
MLOps “done right” addresses sustainable model operations, explainability,
trust, versioning, reproducibility, training updates, and governance (i.e., the
monitoring of very important operational ML characteristics: data drift,
concept drift, and model security).
3) Concept drift by COVID – as mentioned above, concept drift is being addressed in machine learning and data science projects by MLOps, but concept drift is so much bigger than MLOps. Specifically, it feels to many of us like a decade of business transformation was compressed into the one year 2020. How and why businesses make decisions, customers make decisions, and anybody else makes decisions became conceptually and contextually different in 2020. Customer purchase patterns, supply chain, inventory, and logistics represent just a few domains where we saw new and emergent behaviors, responses, and outcomes represented in our data and in our predictive models. The old models were not able to predict very well based on the previous year’s data since the previous year seemed like 100 years ago in “data years”. Another example was in new data-driven cybersecurity practices introduced by the COVID pandemic, including behavior biometrics (or biometric analytics), which were driven strongly by the global “work from home” transition, where many insecurities in networks, data-sharing, and collaboration / communication tools were exposed. Behavior biometrics may possibly become the essential cyber requirement for unique user identification, finally putting weak passwords out of commission. Data and network access controls have similar user-based permissions when working from home as when working behind the firewall at your place of business, but the security checks and usage tracking can be more verifiable and certified with biometric analytics. This is critical in our massively data-sharing world and enterprises.
4) AIOps increasingly became a focus in AI
strategy conversations. While it is similar to MLOps, AIOps is less focused on
the ML algorithms and more focused on automation and AI applications in the
enterprise IT environment – i.e., focused on operationalizing AI, including
data orchestration, the AI platform, AI outcomes monitoring, and cybersecurity
requirements. AIOps appears in discussions related to ITIM (IT infrastructure
monitoring), SIEM (security information and event management), APM (application
performance monitoring), UEBA (user and entity behavior analytics), DevSecOps,
Anomaly Detection, Rout Cause Analysis, Alert Generation, and related
enterprise IT applications.
5) The emergence of Edge-to-Cloud
architectures clearly began pushing Industry 4.0 forward (with some folks now starting
to envision what Industry 5.0 will look like). The Edge-to-Cloud architectures are
responding to the growth of IoT sensors and devices everywhere, whose
deployments are boosted by 5G capabilities that are now helping to
significantly reduce data-to-action latency. In some cases, the analytics and
intelligence must be computed and acted upon at the edge (Edge Computing, at
the point of data collection), as in autonomous vehicles. In other cases, the
analytics and insights may have more significant computation requirements and
less strict latency requirements, thus allowing the data to be moved to larger
computational resources in the cloud. The almost forgotten “orphan”
in these architectures, Fog Computing (living between edge and cloud), is now moving
to a more significant status in data and analytics architecture design.
6) Federated Machine Learning (FML)
is another “orphan” concept (formerly called Distributed Data Mining
a decade ago) that found new life in modeling requirements, algorithms, and
applications in 2020. To some extent, the pandemic contributed to this
because FML enforces data privacy by essentially removing
data-sharing as a requirement for model-building across multiple datasets,
multiple organizations, and multiple applications. FML model training is done incrementally
and locally on the local dataset, with the meta-parameters of the local models
then being shared with a centralized model-inference engine (which does not see
any of the private data). The centralized ML engine then builds a global model,
which is communicated back to the local nodes. Multiple iterations in
parameter-updating and hyperparameter-tuning can occur between local nodes and
the central inference engine, until satisfactory model performance is achieved.
All through these training stages, data privacy is preserved, while allowing
for the generation of globally useful, distributable, and accurate models.
7) Deep learning (DL) may not be “the one
algorithm to dominate all others” after all. There was some research published
earlier in 2020 that found that traditional, less complex algorithms can be
nearly as good or better than deep learning on some tasks. This could be yet
another demonstration of the “no free lunch theorem”, which basically states
that there is no single universal algorithm that is the best for all problems.
Consequently, the results of the new DL research may not be so surprising, but
they certainly prompt us with necessary reminders that sometimes simple is
better than complexity, and that the old saying is often still true: “perfect
is the enemy of good enough.”
8) RPA (Robotic Process Automation) and
intelligent automation were not new in 2020, but the surge in their use
and in the number of providers was remarkable. While RPA is more rule-based
(informed by business process mining, to automate work tasks that have very
little variation), intelligent automation is more data-driven, adaptable, and
self-learning in real-time. RPA mimics human actions, by repetition of routine
tasks based on a set of rules. Intelligent automation simulates human
intelligence, which responds and adapts to emergent patterns in new data, and
which is capable of learning to automate non-routine tasks. Keep an eye on the
intelligent automation space for new and exciting developments to come in the
near future around hyperautomation and enterprise intelligence, such as the
emergence of learning business systems that learn and adapt their processes
based on signals in enterprise data across numerous business functions:
finance, marketing, HR, customer service, production, operations, sales, and
management.
9) The Rise of Data Literacy initiatives,
imperatives, instructional programs, and institutional awareness in 2020 was
one of the two most exciting things that I witnessed during the year. (The
other one of the two is next on my list.) I have said for nearly 20 years that
data literacy must become a key component of education at all levels and an
aptitude of nearly all employees in all organizations. The world is data,
revolves around data, produces and consumes massive quantities of data, and
drives innovative emerging technologies that are inspired by, informed by, and
fueled by data: augmented reality (AR), virtual reality (VR), autonomous
vehicles, computer vision, digital twins, drones, robotics, AI, IoT, hyperautomation,
virtual assistants, conversational AI, chatbots, natural language understanding
and generation (NLU, NLG), automatic language translation, 4D-printing, cyber
resilience, and more. Data literacy is essential for future of work, future
innovation, work from home, and everyone that touches digital information.
Studies have shown that organizations that are not adopting data literacy
programs are not only falling behind, but they may stay behind, their
competition. Get on board with data literacy! Now!
10) Observability emerged as one of the hottest and (for me) most exciting developments of the year. Do not confuse observability with monitoring (specifically, with IT monitoring). The key difference is this: monitoring is what you do, and observability is why you do it. Observability is a business strategy: what you monitor, why you monitor it, what you intend to learn from it, how it will be used, and how it will contribute to business objectives and mission success. But the power, value, and imperative of observability does not stop there. Observability meets AI – it is part of the complete AIOps package: “keeping an eye on the AI.” Observability delivers actionable insights, context-enriched data sets, early warning alert generation, root cause visibility, active performance monitoring, predictive and prescriptive incident management, real-time operational deviation detection (6-Sigma never had it so good!), tight coupling of cyber-physical systems, digital twinning of almost anything in the enterprise, and more. And the goodness doesn’t stop there. The emergence of standards, like OpenTelemetry, can unify all aspects of your enterprise observability strategy: process instrumentation, sensing, metrics specification, context generation, data collection, data export, and data analysis of business process performance and behavior monitoring in the cloud. This plethora of benefits is a real game-changer for open-source self-service intelligent data-driven business process monitoring (BPM) and application performance monitoring (APM), feedback, and improvement. As mentioned above, monitoring is “what you are doing”, and observability is “why you are doing it.” If your organization is not having “the talk” about observability, now is the time to start – to understand why and how to produce business value through observability into the multitude of data-rich digital business applications and processes all across the modern enterprise. Don’t drown in those deep seas of data. Instead, develop an Observability Strategy to help your organization ride the waves of data, to help your business innovation and transformation practices move at the speed of data.
In summary, my top 10 data innovation trends from 2020 are:
GPT-3
MLOps
Concept Drift by COVID
AIOps
Edge-to-Cloud and Fog
Computing
Federated Machine
Learning
Deep Learning meets
the “no free lunch theorem”
RPA and Intelligent
Automation
Rise of Data Literacy
Observability
If
I were to choose what was hottest trend in 2020, it would not be a single item in
this top 10 list. The hottest trend would be a hybrid (convergence) of several of
these items. That hybrid would include: Observability, coupled with Edge and
the ever-rising ubiquitous IoT (sensors on everything), boosted by 5G and cloud
technologies, fueling ever-improving ML and DL algorithms, all of which are
enabling “just-in-time” intelligence and intelligent automation (for
data-driven decisions and action, at the point of data collection), deployed with
a data-literate workforce, in a sustainable and trusted MLOps environment,
where algorithms, data, and applications work harmoniously and are governed and
secured by AIOps.
If we
learned anything from the year 2020, it should be that trendy technologies do not
comprise a menu of digital transformation solutions to choose from, but there really
is only one combined solution, which is the hybrid convergence of data
innovation technologies. From my perspective, that was the single most
significant data innovation trend of the year 2020.
The determination of winners and losers in the data analytics space is a much more dynamic proposition than it ever has been. OneCIO said it this way, “If CIOs invested in machine learning three years ago, they would have wasted their money. But if they wait another three years, they will never catch up.” Well, that statement was made five years ago! A lot has changed in those five years, and so has the data landscape.
The dynamic changes of the business requirements and
value propositions around data analytics have been increasingly intense in
depth (in the number of applications in each business unit) and in breadth (in
the enterprise-wide scope of applications in all business units in all
sectors). But more significant has been the acceleration in the number of dynamic,
real-time data sources and corresponding dynamic, real-time analytics
applications.
We no longer should worry about “managing data at the
speed of business,” but worry more about “managing business at the speed of
data.”
One of the primary drivers for the phenomenal growth in dynamic real-time data analytics today and in the coming decade is the Internet of Things (IoT) and its sibling the Industrial IoT (IIoT). With its vast assortment of sensors and streams of data that yield digital insights in situ in almost any situation, the IoT / IIoT market has a projected market valuation of $1.5 trillion by 2030. The accompanying technology Edge Computing, through which those streaming digital insights are extracted and then served to end-users, has a projected valuation of $800 billion by 2028.
With dynamic real-time insights, this “Internet
of Everything” can then become the “Internet of Intelligent Things”, or as I
like to say, “The Internet used to be a thing. Now things are the Internet.”
The vast scope of this digital transformation in dynamic business insights
discovery from entities, events, and behaviors is on a scale that is almost
incomprehensible. Traditional business analytics approaches (on laptops, in the
cloud, or with static datasets) will not keep up with this growing tidal wave
of dynamic data.
Another dimension to this story, of course, is the Future of Work discussion, including creation of new job titles and roles, and the demise of older job titles and roles. One group has declared, “IoT companies will dominate the 2020s: Prepare your resume!” This article quotes an older market projection (from 2019), which estimated “the global industrial IoT market could reach $14.2 trillion by 2030.”
In
dynamic data-driven applications, automation of the essential processes (in
this case, data triage, insights discovery, and analytics delivery) can give a
power boost to ride that tidal wave of fast-moving data streams. One can
prepare for and improve skill readiness for these new business and career
opportunities in several ways:
Focus on the automation of business processes: e.g., artificial intelligence, robotics, robotic process automation, intelligent process automation, chatbots.
Focus on the technologies and engineering components: e.g., sensors, monitoring, cloud-to-edge, microservices, serverless, insights-as-a-service APIs, IFTTT (IF-This-Then-That) architectures.
Focus on the data science: e.g., machine learning, statistics, computer vision, natural language understanding, coding, forecasting, predictive analytics, prescriptive analytics, anomaly detection, emergent behavior discovery, model explainability, trust, ethics, model monitoring (for data drift and concept drift) in dynamic environments (MLOps, ModelOps, AIOps).
Focus on specific data types: e.g., time series, video, audio, images, streaming text (such as social media or online chat channels), network logs, supply chain tracking (e.g., RFID), inventory monitoring (SKU / UPC tracking).
Focus on the strategies that aim these tools, talents, and technologies at reaching business mission and goals: e.g., data strategy, analytics strategy, observability strategy (i.e., why and where are we deploying the data-streaming sensors, and what outcomes should they achieve?).
Insights
discovery from ubiquitous data collection (via the tens of billions of
connected devices that will be measuring, monitoring, and tracking nearly
everything internally in our business environment and contextually in the
broader market and global community) is ultimately about value creation and business
outcomes. Embedding real-time dynamic analytics at the edge, at the point of
data collection, or at the moment of need will dynamically (and positively) change
the slope of your business or career trajectory. Dynamic sense-making, insights
discovery, next-best-action response, and value creation is essential when data
is being acquired at an enormous rate. Only then can one hope to realize the
promised trillion-dollar market value of the Internet of Everything.
For more advice, check out this upcoming webinar panel discussion, sponsored by AtScale, with data and analytics leaders from Wayfair, Cardinal Health, bol.com, and Slickdeals: “How to make smarter data-driven decisions at scale.” Each panelist will share an overview of their data & analytics journey, and how they are building a self-service, data-driven culture that scales. Join us on Wednesday, March 31, 2021 (11:00am PT | 2:00pm ET). Save your spot here: http://bit.ly/3rS3ZQW. I hope that you find this event useful. And I hope to see you there!
I have written articles in many places. I will be collecting links to those sources here. The list is not complete and will be constantly evolving. There are some older blogs that I will be including in the list below as I remember them and find them. Also included are some interviews in which I provided detailed answers to a variety of questions.
And then there’s this — not a blog, but a link to my 2013 TedX talk: “Big Data, Small World.” (Many more videos of my talks are available online. That list will be compiled in another place soon.)
50 years after the publication of Alvin Toffler’s landmark book “Future Shock“, a new book “After Shock” is here. This 540-page compendium collects over 100 modern-day perspectives on After Shock from leading futurists, including deep assessments of Toffler’s formidably prescient predictions from half a century ago, along with a status check on the current exponential growth (“shock”) in all sectors of the world economy, from the unique vantage points of many different contributors. Contributors include David Brin, Po Bronson, Sanjiv Chopra, George Gilder, Newt Gingrich, Alan Kay, Ray Kurzweil, Jane McGonigal, Lord Martin Rees, Byron Reese, and many others. I am honored to be included among those luminary contributors. I present here a short excerpt from my contribution to the book.
After Shock, edited by John Schroeter
“Shocking Amount of Data”
An excerpt from my chapter in the book:
“We are fully engulfed in the era of massive data collection. All those data represent the most critical and valuable strategic assets of modern organizations that are undergoing digital disruption and digital transformation. Advanced analytics tools and techniques drive insights discovery, innovation, new market opportunities, and value creation from the data. However, our enthusiasm for “big data” is tempered by the fact that this data flood also drives us to sensory input shock and awe.
“Among the countless amazing foresights that appeared in Alvin Toffler’s Future Shock was the concept of information overload. His discussion of the topic came long before the creation and proliferation of social networks, the World Wide Web, the Internet, enterprise databases, ubiquitous sensors, and digital data collection by all organizations—big and small, public and private, near and far. The clear and present human consequences and dangers of infoglut were succinctly called out as section headings in Chapter 16 “The Psychological Dimension” of Toffler’s book, including these: “the overstimulated individual,” “bombardment of the senses” and “decision stress.”
“While these ominous forecasts have now become a reality for our digitally drenched society, especially for the digital natives who have known no other experience, there is hope for a lifeline that we can grasp while swimming (or drowning) in that sea of data. And that hope emanates from the same foundation that is the basis of the information overload shock itself. That foundation is data, and the hope is AI – artificial intelligence. The promise of AI is entirely dependent on the flood of sensory input data that fuels the advanced algorithms that activate and stimulate the Actionable Insights (representing another definition of A.I.), which is what AI is really aimed at achieving.
“AI is a great producer of dichotomous reactions in society: hype versus hope, concern versus commercialization, fantasy versus forward-thinking, overstimulation versus overabundance of opportunity, bombardment of the senses versus bountiful insights into solving hard problems, and decision stress versus automated decision support. Could we imagine any technology that has more mutually contradictory psychological dimensions than AI? I cannot.
“AI takes its cue from data. It needs data – and not just small quantities, but large quantities of data, containing training examples of all sorts of behaviors, events, processes, things, and outcomes. Just as a human (or any cognitive creature) receives sensory inputs from its world through multiple channels (e.g., our five senses) and then produces an output—make a decision, take an action—in response to those inputs, similarly that is exactly what an AI does. The AI relies on mathematical algorithms that sort through streams of data, to find the most relevant, informative, actionable, and pertinent patterns in the data. From those presently perceived patterns, AI then produces an output (decision and/or action). For example, when a human detects and then recognizes a previously seen pattern, the person knows how to respond—what to decide and how to act. This is what an AI is being trained to do automatically and with minimal human intervention through the data inputs that cue the algorithms.
“How AI helps with infoglut and thereby addresses the themes of Toffler’s writings (“information overload”, “overstimulation and bombardment of the senses”, and “decision stress”) is through…
…”
You can continue reading my chapter, plus dozens more perspectives, in the full After Shock book here: https://amzn.to/2S01MC7
Definitions of terminology frequently seen and used in discussions of emerging digital technologies.
Additive Manufacturing: see 3D-Printing
AGI (Artificial General Intelligence): The intelligence of a machine that has the capacity to understand or learn any intellectual task that a human being can. It is a primary goal of some artificial intelligence research and a common topic in science fiction and future studies.
AI (Artificial Intelligence): Application of Machine Learning algorithms to robotics and machines (including bots), focused on taking actions based on sensory inputs (data). Examples: (1-3) All those applications shown in the definition of Machine Learning. (4) Credit Card Fraud Alerts. (5) Chatbots (Conversational AI). There is nothing “artificial” about the applications of AI, whose tangible benefits include Accelerated Intelligence, Actionable Intelligence (and Actionable Insights), Adaptable Intelligence, Amplified Intelligence, Applied Intelligence, Assisted Intelligence, and Augmented Intelligence.
Algorithm: A set of rules to follow to solve a problem or to decide on a particular action (e.g., the thermostat in your house, or your car engine alert light, or a disease diagnosis, or the compound interest growth formula, or assigning the final course grade for a student).
Analytics: The products of Machine Learning and Data Science (such as predictive analytics, health analytics, cyber analytics).
AR (Augmented Reality): A technology that superimposes a computer-generated image on a user’s view of the real world, thus providing a composite view. Examples: (1) Retail. (2) Disaster Response. (3) Machine maintenance. (4) Medical procedures. (5) Video games in your real world. (6) Clothes shopping & fitting (seeing the clothes on you without a dressing room). (7) Security (airports, shopping malls, entertainment & sport events).
Autonomous Vehicles: Self-driving (guided without a human), informed by data streaming from many sensors (cameras, radar, LIDAR), and makes decisions and actions based on computer vision algorithms (ML and AI models for people, things, traffic signs,…). Examples: Cars, Trucks, Taxis
BI (Business Intelligence): Technologies, applications and practices for the collection, integration, analysis, and presentation of business information. The purpose of Business Intelligence is to support better business decision-making.
Big Data: An expression that refers to the current era in which nearly everything is now being quantified and tracked (i.e., data-fied). This leads to the collection of data and information on nearly full-population samples of things, instead of “representative subsamples”. There have been many descriptions of the characteristics of “Big Data”, but the three dominant attributes are Volume, Velocity, and Variety — the “3 V’s” concept was first introduced by Doug Laney in 2001 here. Read more in this article: “Why Today’s Big Data is Not Yesterday’s Big Data“. Some consider the 2011 McKinsey & Company research report “Big Data: The Next Frontier for Innovation, Competition, and Productivity” as the trigger point when the world really started paying attention to the the volume and variety of data that organizations everywhere are collecting — the report stated, “The United States alone could face a shortage of 140,000 to 190,000 people with deep analytical skills as well as 1.5 million managers and analysts with the know-how to use the analysis of big data to make effective decisions.”
Blockchain: A system in which a permanent and verifiable record of transactions is maintained across several computers that are linked in a peer-to-peer network. It has many applications beyond its original uses for bitcoin and other cryptocurrencies. Blockchain in an example of Distributed Ledger Technology, in which independent computers (referred to as nodes) record, share and synchronize transactions in their respective electronic ledgers (instead of keeping data centralized as in a traditional ledger). Blockchain’s name refers to a chain (growing list) of records, called blocks, which are linked using cryptography, and are used to record transactions between two parties efficiently and in a verifiable and permanent way. In simplest terms, Blockchain is a distributed database existing on multiple computers at the same time. It grows as new sets of recordings, or ‘blocks’, are added to it, forming a chain. The database is not managed by any particular body; instead, everyone in the network gets a copy of the whole database. Old blocks are preserved forever and new blocks are added to the ledger irreversibly, making it impossible to manipulate by faking documents, transactions and other information. All blocks are encrypted in a special way, so everyone can have access to all the information but only a user who owns a special cryptographic key is able to add a new record to a particular chain.
Chatbots (see also Virtual Assistants): These typically are text-based user interfaces (often customer-facing for organizations) that are designed and programmed to reply to only a certain set of questions or statements. If the question asked is other than the learned set of responses by the customer, the chatbot will fail. Chatbots cannot hold long, continuing human interaction. Traditionally they are text-based but audio and pictures can also be used for interaction. They provide more like an FAQ (Frequently Asked Questions) type of an interaction. They cannot process language inputs generally.
Cloud: The cloud is a metaphor for a global network of remote servers that operates transparently to the user as a single computing ecosystem, commonly associated with Internet-based computing.
Cloud Computing: The practice of using a network of remote servers hosted on the Internet to store, manage, and process data, rather than a local server, local mainframe, or a personal computer.
Computer Vision: An interdisciplinary scientific field that focuses on how computers can be made to gain high-level understanding from digital images or videos. From the perspective of engineering, it seeks to automate tasks that the human visual system can do, including pattern detection, pattern recognition, pattern interpretation, and pattern classification.
Data Mining: Application of Machine Learning algorithms to large data collections, focused on pattern discovery and knowledge discovery in data. Pattern discovery includes clusters (class discovery), correlation (and trend) discovery, link (association) discovery, and anomaly detection (outlier detection, surprise discovery).
Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more).
Digital Transformation: Refers to the novel use of digital technology to solve traditional problems. These digital solutions enable — other than efficiency via automation — new types of innovation and creativity, rather than simply enhance and support traditional methods.
Digital Twins: A phrase used to describe a computerized (or digital) version of a real physical asset and/or process. The digital twin contains one or more sensors that collects data to represent real-time information about the physical asset. By bridging the physical and the virtual world, data is transmitted seamlessly allowing the virtual entity to exist simultaneously with the physical entity. Digital Twins are used in manufacturing, large-scale systems (such as maritime vessels, wind farms, space probes) and other complex systems. Digital Twins are virtual replicas of physical devices that data scientists and IT pros can use to run simulations before actual devices are built and deployed, and also while those devices are in operation. They represent a strong merging and optimization of numerous digital technologies such as IoT (IIoT), AI, Machine Learning, and Big Data Analytics.
Drone (UAV, UAS): An unmanned aerial vehicle (UAV) or uncrewed aerial vehicle (commonly known as a Drone) is an aircraft without a human pilot on board. UAVs are a component of an unmanned aircraft system (UAS); which include a UAV, a ground-based controller, and a system of communications between the two.
Dynamic Data-driven Application (Autonomous) Systems (DDDAS): A paradigm in which the computation and instrumentation aspects of an application system are dynamically integrated in a feed-back control loop, such that instrumentation data can be dynamically incorporated into the executing model of the application, and in reverse the executing model can control the instrumentation. Such approaches can enable more accurate and faster modeling and analysis of the characteristics and behaviors of a system and can exploit data in intelligent ways to convert them to new capabilities, including decision support systems with the accuracy of full scale modeling, efficient data collection, management, and data mining. See http://dddas.org/.
Edge Computing (and Edge Analytics): A distributed computing paradigm which brings computation to the data, closer to the location where it is needed, to improve response times in autonomous systems and to save bandwidth. Edge Analytics specifically refers to an approach to data collection and analysis in which an automated analytical computation is performed on data at a sensor, network switch or other device instead of waiting for the data to be sent back to a centralized data store. This is important in applications where the result of the analytic computation is needed as fast as possible (at the point of data collection), such as in autonomous vehicles or in digital manufacturing.
Industry 4.0: A reference to a new phase in the Industrial Revolution that focuses heavily on interconnectivity, automation, Machine Learning, and real-time data. Industry 4.0 is also sometimes referred to as IIoT (Industrial Internet of Things) or Smart Manufacturing, because it joins physical production and operations with smart digital technology, Machine Learning, and Big Data to create a more holistic and better connected ecosystem for companies that focus on manufacturing and supply chain management.
IoT (Internet of Things) and IIoT (Industrial IoT): Sensors embedded on devices and within things everywhere, measuring properties of things, and sharing that data over the Internet (over fast 5G), to fuel ML models and AI applications (including AR and VR) and to inform actions (robotics, autonomous vehicles, etc.). Examples: (1) Wearable health devices (Fitbit). (2) Connected cars. (3) Connected products. (4) Precision farming. (5) Industry 4.0
Knowledge Graphs (see also Linked Data): Knowledge graphs encode knowledge arranged in a network of nodes (entities) and links (edges) rather than tables of rows and columns. The graph can be used to link units of data (the nodes, including concepts and content), with a link (the edge) that explicitly specifies what type of relationship connects the nodes.
Linked Data (see also Knowledge Graphs): A data structure in which data items are interlinked with other data items that enables the entire data set to be more useful through semantic queries. The easiest and most powerful standard designed for Linked Data is RDF (Resource Description Framework).
Machine Learning (ML): Mathematical algorithms that learn from experience (i.e., pattern detection and pattern recognition in data). Examples: (1) Digit detection algorithm (used in automated Zip Code readers at Post Office. (2) Email Spam detection algorithm (used for Spam filtering). (3) Cancer detection algorithm (used in medical imaging diagnosis).
MR (Mixed Reality): Sometimes referred to as hybrid reality, is the merging of real and virtual worlds to produce new environments and visualizations where physical and digital objects co-exist and interact in real time. It means placing new imagery within a real space in such a way that the new imagery is able to interact, to an extent, with what is real in the physical world we know. The key characteristic of MR is that the synthetic content and the real-world content are able to react to each other in real time.
NLP (Natural Language Processing), NLG (NL Generation), NLU (NL Understanding): NLP a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human languages, in particular how to program computers to process and analyze large amounts of natural language data. NLG is a software process that transforms structured data into human-language content. It can be used to produce long form content for organizations to automate custom reports, as well as produce custom content for a web or mobile application, or produce the words that will be spoken by a Virtual (Voice-based) Assistant. NLU is a subtopic of Natural Language Processing in Artificial Intelligence that deals with algorithms that have language comprehension (understanding the meaning of the words, both their content and their context).
Quantum Computing: The area of study focused on developing computer technology based on the principles of quantum theory and quantum phenomena (such as superposition of states and entanglement). Qubits are the fundamental units of quantum computing — they are somewhat analogous to bits in a classical computer.
Robotics: A branch of AI concerned with creating devices that can move and react to sensory input (data). Examples: (1) Automated manufacturing assembly line. (2) Roomba (vacuums your house). (3) Warehouse / Logistics. (4) Prosthetics.
Statistics: the practice or science of collecting and analyzing numerical data, especially for the purpose of inferring proportions in a whole population from measurements of those properties within a representative subsample.
UAV (Unmanned Aerial Vehicle) and UAS (Unmanned Aircraft System): see Drones.
Virtual Assistants (see also Chatbots): A sophisticated voice-based interface in an interactive platform for user and customer interactions. Virtual assistants understand not only the language but also the meaning of what the user is saying. They can learn from their conversation instances, which can lead to an unpredictability in their behavior. Consequently, they can have extended adaptable human interaction. They can be set to perform slightly complicated tasks as well, such as order-taking and task fulfillment.
VR (Virtual Reality): Computer-generated simulation of a three-dimensional environment that can be interacted with in a seemingly real or physical way by a person using special electronic equipment, such as a helmet with a screen inside or gloves fitted with sensors. Examples: (1) Games. (2) Family adventures. (3) Training & Education. (4) Design. (5) Big Data Exploration.
XAI (eXplainable AI, Trusted AI): Artificial intelligence that is programmed to describe (explain) its purpose, rationale and decision-making process in a way that can be understood by the average person. This includes the specific criteria the program uses to arrive at a decision.
XPU: One of the many specialized CPUs for specific applications (similar to an ASIC), which may be real-time, data-intensive, data-specific, or at the edge (see Edge Analytics). For more information, refer to the article “Sensor Analytics at Micro Scale on the xPU“.
3D-Printing … moving on to 4D-printing: Additive Manufacturing — the action or process of making a physical object from a three-dimensional digital model, typically by laying down many thin layers of a material in succession. The terms “additive manufacturing” and “3D printing” both refer to creating an object by sequentially adding build material in successive cross-sections, one stacked upon another.
5G: Fifth-generation wireless, the latest iteration of cellular technology, engineered to greatly increase the speed and responsiveness of wireless networks. 5G will also enable a sharp increase in the amount of data transmitted over wireless systems due to more available bandwidth. Example applications: (1) High-definition and 3D video. (2) Gbit/sec Internet. (3) Broadband network access nearly everywhere. (4) IoT.
We often think of analytics on large scales, particularly in the context of large data sets (“Big Data”). However, there is a growing analytics sector that is focused on the smallest scale. That is the scale of digital sensors — driving us into the new era of sensor analytics.
Small scale (i.e., micro scale) is nothing new in the digital realm. After all, the digital world came into existence as a direct consequence of microelectronics and microcircuits. We used to say in the early years of astronomy big data (which is my background) that the same transistor-based logic microcircuitry that comprises our data storage devices (which are storing massive streams of data) is essentially the same transistor-based logic microcircuitry inside our sensors (which are collecting that data). The latter includes, particularly, the sensors inside digital cameras, consisting of megapixels and even gigapixels. Consequently, there should be no surprise that the two digital data functions (sensing and storing) are intimately connected and that we are therefore drowning in oceans of data.
But, in our rush to crown data “big”, we sometimes may have forgotten that micro-scale component to the story. But not any longer. There is growing movement in the microchip world in new and interesting directions.
I am not only talking about evolutions of the CPU (central processing unit) that we have seen for years: the GPU (graphics processing unit) and the FPGA (field programmablegate array). We are now witnessing the design, development, and deployment of more interesting application-specific integrated circuits (ASICs), one of which is the TPU (tensor processing unit) which is specifically designed for AI (artificial intelligence) applications. The TPU (as its name suggests) can perform tensor calculations on the chip, in the same way that earlier generation integrated circuits were designed to perform scalar operations (in the CPU) and to perform vector and/or parallel streaming operations (in the GPU).
Speeding the calculations is precisely the goal of these new chips. One that I heard discussed in the context of cybersecurity applications is the BPU (Behavior Processing Unit), designed to detect BOI (behaviors of interest). Whereas the TPU might be detecting persons of interest (POI) or objects of interest in an image, the BOI is looking at patterns in the time series (sequence data) that are indicative of interesting (and/or anomalous) behavioral patterns.
The BOI detector (the BPU) would definitely represent an amplifier to cybersecurity operations, in which the massive volumes of data streaming through our networks and routers are so huge that we never actually capture (and store) all of that data. So we need to detect the anomalous pattern in real-time before a damaging cyber incident occurs!
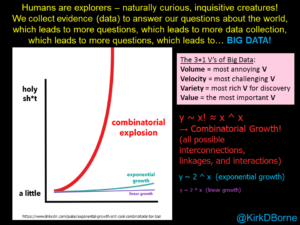
In the early days of the big data era (at the peak of the big data hype), we would often hear about the 3 V’s of big data (Volume, Variety, and Velocity). Then, people started adding more V’s, including Veracity and Value, plus many more! I was guilty of adding several more in my article “Top 10 Big Data Challenges – A Serious Look at 10 Big Data V’s“.
Through the years, I have decided on the following “4 V’s of Big Data” summary in my own presentations:
Volume = the most annoying V
Velocity = the most challenging V
Variety = the most rich V for insights discovery, innovation, and better decisions
Value = the most important V
As Dez Blanchfield once said, “You don’t need a data scientist to tell you big data is valuable. You need one to show its value.”
A series of articles that drive home the all-important value of data is being published on the DataMakesPossible.com site. The site’s domain name says it all: Data Makes Possible!
What does data make possible? I occasionally discuss these things in articles that I write for the MapR blog series, where I have summarized the big data value proposition very simply in my own list of the 3 D2D‘s of big data:
Data-to-Discovery (Class Discovery, Correlation Discovery, Novelty Discovery, Association Discovery)
Data-to-Decisions
Data-to-Dollars (or Data-to-Dividends)
The story is richer and much more impactful these days than those trivial 1-letter (V) or 3-letter (D2D) mnemonics would suggest. We are far past the peak of inflated expectations in the big data hype cycle, and we are even beyond the trough of disillusionment. We have truly entered the plateau of productivity from data in our organizations, though the analytics-driven culture is still going through growing pains.
So, what does data make possible? I document our progress toward deriving big value from big data in a series of articles that I am writing (with more to come) for the DataMakesPossible.com site. These articles include:
But don’t stop there! There are many more fabulous articles, insights, case studies, and impactful stories at DataMakesPossible.com — visit the site often, as there are new posts every week.
Let’s improve our world together through the insights and discoveries that large, comprehensive data collections can provide! That’s what data scientists love to do.