
A wise philosopher (or comedian) once said, “Even a broken clock is right twice a day.” That same statement might also apply to some predictive models. Since prediction is about the future (usually), then random chance (like broken clockwork) may allow our model to be right occasionally (just by accident). The important step in the data science process that aims to reduce the danger of this occurring is the all-important cross-validation phase (or model-testing phase, which uses an independent data set). This phase is devoted to validating that our model works accurately on previously unseen data that were not used in the model training (model-building) phase.
Another way of characterizing this phase can be found in the field of System Engineering: V&V (Verification and Validation). In the first phase (verification), we verify that the system was built correctly (according to a set of requirements and specifications). In the second phase (validation), we validate that we built the correct system (consistent with the operational needs that the end-user, customer, or client expects the system to satisfy). We sometimes say it this way: (1) in verification, we ask “Did we build the system right?”; and (2) in validation, we ask “Did we build the right system?”
Applying the V&V system engineering principle to data science means that we see model-testing as a two-step process. First, we verify that the model is a logical consequent of the input data used to train the model. Second, we validate that the model remains useful, accurate, and robust when applied to previously unseen data. Any data scientist who participates in Kaggle competitions understands and “lives” this process. It is often the case that our first data science model will do a great job on the “seen” data set (i.e., verification by using a “broken clock” that is right on occasion), but the model then performs poorly on the “unseen” data set. A model that does well on both data sets is a winning model (maybe not in every Kaggle competition, but certainly in real-world usage).
Using the same data set both to validate a model and to train the model would be the data science equivalent of “circular reasoning“. This will often lead to “overfitting“, where the initial model is incorrectly trained to reproduce every variation, bump, wiggle, nuance, and noisy deviation in the training data set, thus falsely exaggerating the importance of those fluctuations. “Complexity” describes our world, but it shouldn’t describe our models.
The other extreme in model-building can be just as bad: underfitting (or bias) introduced by using too few explanatory variables to model the behaviors seen in our data set. I like to believe that Albert Einstein understood data science modeling very well when he said “Everything should be made as simple as possible, but not simpler.” Building an excessively complex model (with too many parameters that follow the noise fluctuations in our data) is like putting too much confidence in a broken clock (“it’s exactly right… some of the time!”). George Box warned us to have a little humility in the face of complex data (and a complex world): “All models are wrong, but some are useful.”
Therefore, when faced with highly complex (high-variety) big data, we are also faced with how to choose the “right model”. We should apply the “Goldilocks principle” — choose a model that is not “too good” and not too bad (i.e., the model works well enough on the training data set and on the test data set).
Follow Kirk Borne on Twitter @KirkDBorne
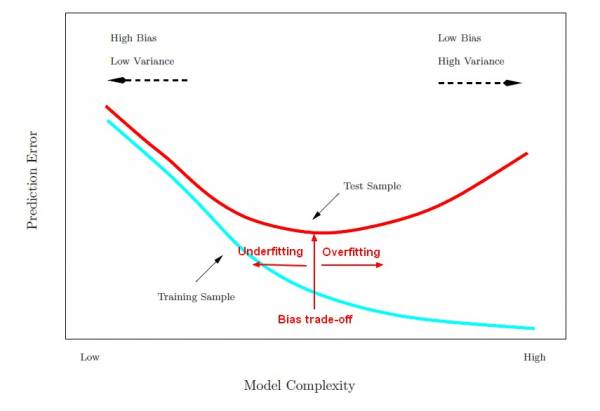
(Source for graphic: http://gerardnico.com/wiki/data_mining/bias_trade-off)