Pure Storage empowers enterprise AI with advanced data storage technologies and validated reference architectures for emerging generative AI use cases.
Summary
AI devours data. With award-winning AI-ready infrastructure, an AI data platform, and collaboration with NVIDIA, Pure Storage is delivering solutions and services that enable organizations to manage the high-performance data and compute requirements of enterprise AI.
AI Then and AI Now
They (some wise anonymous folks out there) say that there is a time and place for everything. They also say there is a season for every purpose. I believe that the time, place, and season for artificial intelligence (AI) data platforms have arrived. To see this, look no further than Pure Storage, whose core mission is to “empower innovators by simplifying how people consume and interact with data.”
In the past, it was sufficient to bring order to the randomness of enterprise data collection through applications of technology resources (databases and storage devices) that were aimed primarily at organizing, storing, indexing, and managing enterprise information assets for single purposes or single business units. However, this data was still left mostly unexploited for its maximum potential and enterprise-wide business value.
Also in the past, it was sufficient for business automation to consist primarily of rigid rule-based robotic non-adaptive repetition of processes and fixed tasks, requiring very little (if any) new knowledge input (i.e., live data consumption) or real-time adaptation to changing business conditions.
And also in the past, it was sufficient for AI to be relegated to academic researchers or R&D departments of big organizations who mostly produced research reports or journal papers, and not much else.
Fast-forward to 2024 and we see a totally different landscape: massive data sets feeding dynamic cross-enterprise processes, increasing automation and dynamic adaption of complex multi-step tasks, and ubiquitous value-producing applications of AI. In particular, in the past year, generative AI has played a major role in the explosive development and growth of these transformations within enterprises.
Pure Storage Meets the Demands of Enterprise AI
To support, sustain, and assure the continued success and cost-effectiveness of the enormous data-fueled AI-powered transformations in such a rapidly changing environment, Pure Storage has stepped up their delivery of an incredible array of award-winning AI-ready infrastructure (AIRI//S™) products and services with an AI data platform that provides the fundamental AI environment for enterprise data management (storage, access, orchestration, delivery), hyperscaled AI training, and AI inference on demand (on-prem, in data centers, at edge sites, and in micro edge devices).
One example of Pure Storage’s advantage in meeting AI’s data infrastructure requirements is demonstrated in their DirectFlash® Modules (DFMs), with an estimated lifespan of 10 years and with super-fast flash storage capacity of 75 terabytes (TB) now, to be followed up with a roadmap that is planning for capacities of 150TB, 300TB, and beyond. Another example is Pure Storage’s FlashBlade® which was invented to help companies handle the rapidly increasing amount of unstructured data coming into greater use, as required in the training of multi-modal AI models. One more example is Pure Storage’s development of non-disruptive upgrades (NDUs), a feature of Pure Storage’s architecture that permits upgrades and expansion of the data infrastructure with no impact on data availability or performance, and with no downtime or data migrations.
Pure Storage’s Announcements at GTC 2024
The preceding examples are industry-leading and exemplary, and yet there’s still more. At the NVIDIA GTC 2024 conference, Pure Storage announced so much more! Here are a few more details on some of those announcements.
A Data Platform for AI
Data is the fuel for AI, because AI devours data—finding patterns in data that drive insights, decisions, and action. Ease of data orchestration (ingest, cleaning, transformation, discovery, access, exploration, delivery, training, inference, deployment) is essential for data-devouring AI products and services. A data platform for AI is key to innovation and long-term affordability, scalability, sustainability, and advancement of enterprise AI applications. Anything less than a complete data platform for AI is a deal-breaker for enterprise AI. Pure Storage provides the ideal data platform for AI, as it provides unified storage for structured and unstructured data and provides enterprise data services for Kubernetes, supporting the entire AI data pipeline, because storage matters!
At GTC 2024, Pure demonstrated the features of their data platform for AI, specifically highlighting these benefits and features of the platform: (a) Helps organizations accelerate model training and inference; (b) Improves operational efficiency for AI/IT infrastructure teams, as well as AI/ML developers and engineers; (c) Delivers cost and energy efficiency as an enterprise scales their AI operations; and (d) Provides an AI storage platform that delivers ultimate reliability and is built to handle all future AI storage needs.
Optimizing GenAI Apps with RAG—Pure Storage + NVIDIA for the Win!
One of the most popular techniques associated with generative AI (GenAI) this past year has been retrieval-augmented generation (RAG). RAG is the essential link between two things: (a) the general large language models (LLMs) available in the market, and (b) a specific organization’s local knowledge base. In deep learning applications (including GenAI, LLMs, and computer vision), a data object (e.g., document, image, video, audio clip) is reduced (transformed) to a condensed vector representation using deep neural networks. The knowledge base then becomes the comprehensive collection of these condensed representations of the enterprise business data repositories, stored in vector format in a vector database—Vector DB being another major data technology development finding widespread adoption this past year.
As a consequence of these activities, RAG provides the bespoke use case-specific context to an organization’s proprietary GenAI LLM applications. This contextualization of the GenAI LLM is not only enterprise-specific, local, and customized, but it is also proprietary—maintaining the privacy and security of the GenAI LLM application within the security firewalls and policies of that organization. Additionally, RAG ensures the use of an organization’s most recent data while eliminating the need for constant retraining of the LLMs. Pure Storage has worked with NVIDIA (GPU memory and GPU servers) to boost the speed, accuracy, and on-prem power of such enterprise GenAI LLM applications. Here are some specific documented results:
(a) “NVIDIA GPUs are used for compute and Pure Storage FlashBlade//S provides all-flash enterprise storage for a large vector database and its associated raw data. In a specific case [presented at GTC], the raw data consisted of a large collection of public documents, typical of a public or private document repository used for RAG.”
Pure Storage’s RAG pipeline, in conjunction with NVIDIA GPUs and NVIDIA’s NeMo Retriever collection of GenAI microservices, ensures accuracy, currency, privacy, and relevance of proprietary enterprise LLMs. Time to insight and time to action in AI applications are faster and better with Pure Storage.
OVX Validated Reference Architecture for AI-ready Infrastructures
First question: What is OVX validation? OVX is NVIDIA’s standard validation paradigm for computing systems that combine high-performance GPU acceleration, graphics, and AI with fast, low-latency networking that are used to design and power complex 3D virtual worlds and digital twins that are transforming how businesses design, simulate, and optimize complex systems and processes. In this fantastic emerging realm of breathtaking technological achievements and innovations, Pure Storage has achieved OVX validation of their reference architecture for AI-ready infrastructures. At this stage, OVX validation applies directly to the increasing business demand for GenAI workloads (including RAG, LLMs, knowledge bases, and Vector DB), full-stack ready-to-run enterprise AI infrastructure, and local proprietary custom data + AI compute, storage, and networking solutions. Note: When you see “full-stack,” read “Pure Storage + NVIDIA working together seamlessly.”
Second question: What about technical debt and the cost of “lift and shift” to these new AI-ready architectures? For Pure Storage, OVX validation also certifies that Pure Storage’s AI-ready infrastructure will run on NVIDIA GPUs and on other vendors’ servers, which is a great savings on technical debt for those organizations that operate diverse server farms. OVX validation complements Pure Storage’s certified reference architecture for NVIDIA DGX BasePOD that was announced last year as well as their FlashStack® for AI Cisco Validated Designs announced here.
Since one of the only certainties about the future is its uncertainty, it is a great benefit that Pure Storage Evergreen//One™ provides storage-as-a-service (STaaS) guarantees and enables future-proof growth with non-disruptive upgrades. That means that Pure Storage owns the hardware (“the end user doesn’t pay for it”), but the end user buys a subscription to the storage with the same agility and flexibility of public cloud storage, and with all the security, proprietary protection, and performance of on-prem all-flash sustainable infrastructure. This is Pure Storage’s SLA-guaranteed cloud-like STaaS!
More Pure Storage Announcements at GTC 2024
Pure Storage’s RAG development (described earlier) is accelerating successful AI adoption across vertical industries. Pure Storage is accomplishing this by creating vertical-specific RAGs in collaboration with NVIDIA. First, “Pure Storage has created a financial services RAG solution to summarize and query massive data sets with higher accuracy than off-the-shelf LLMs. Financial services institutions can now gain faster insight using AI to create instant summaries and analysis from various financial documents and other sources.” Pure Storage will soon release additional RAGs for healthcare and the public sector.
Expanded investment in the AI partner ecosystem: Pure Storage is further investing in its AI partner ecosystem with NVIDIA, engaging in new partnerships with independent software vendors (ISVs). Some of these investments are aimed at optimizing GPU utilization through advanced orchestration and scheduling, and others enable machine learning teams to build, evaluate, and govern their model development lifecycle. Additionally, Pure Storage is working closely with numerous AI-focused resellers and service partners to further operationalize joint customer AI deployments.
Looking at AI Now and at What’s Next
As the award-winning leader in AI-ready (and future-ready) data infrastructure, Pure Storage is collaborating with NVIDIA to empower their global customers with a proven framework to manage the high-performance data and compute requirements that these enterprises need to drive successful AI deployments, both now and into the future. Every technical leader, line of business (LOB) leader, VP of Infrastructure for AI, VP of AI/Data Science, and CDO/CTO/CAIO can benefit right now from these technologies and services.
To put all of Pure Storage’s recent accomplishments, products, services, and solutions into a single statement, I would say that Pure Storage’s primary purpose (their North Star) is to guide and accelerate their customers’ adoption of AI through the Pure Storage platform for AI.
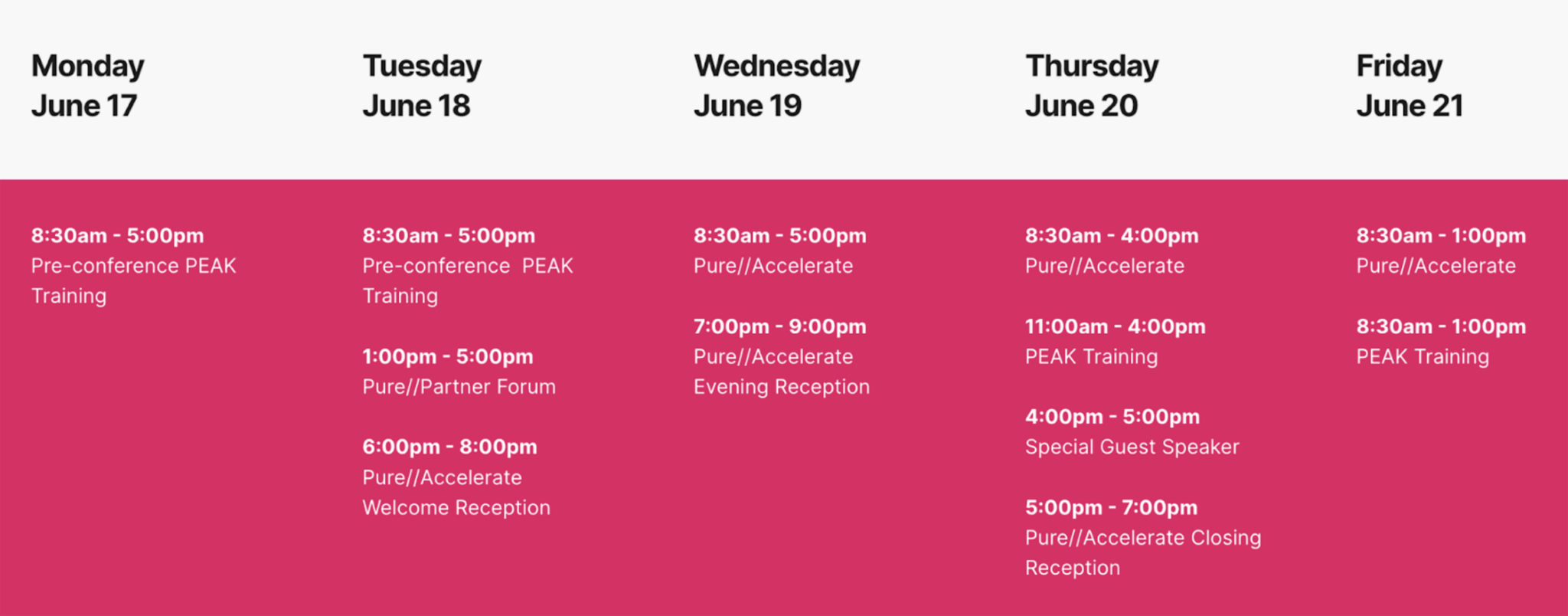
To learn more about all of this, make connections, learn new skills, and get ready for what’s next in this rapidly evolving season of AI, be sure to register and attend the Pure//Accelerate® 2024 live event June 18-21, 2024, at Resorts World Las Vegas. The event will have a special track on “Today’s and Tomorrow’s Applications of AI.” Don’t miss it!
Register Now for Pure//Accelerate 2024
Drive your data success at Pure//Accelerate® at Resorts World Las Vegas from June 18-21. This is the premier event to make connections, learn new skills, and get ready for what’s next. Here’s a sneak peek of what to expect:
I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications. This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative. The results showed that (among those surveyed) approximately 90% of enterprise analytics applications are being built on tabular data. The ease with which such structured data can be stored, understood, indexed, searched, accessed, and incorporated into business models could explain this high percentage. A similarly high percentage of tabular data usage among data scientists was mentioned here.
If my explanation above is the correct interpretation of the high percentage, and if the statement refers to successfully deployed applications (i.e., analytics products, in contrast to non-deployed training experiments, demos, and internal validations of the applications), then maybe we would not be surprised if a new survey (not yet conducted) was to reveal that a similar percentage of value-producing enterprise data innovation and analytics/ML/AI applications (hereafter, “analytics products”) are based on on-premises (on-prem) data sources. Why? … because the same productivity benefits mentioned above for tabular data sources (fast and easy data access) would also be applicable in these cases (on-prem data sources). And no one could deny that these benefits would be substantial. What could be faster and easier than on-prem enterprise data sources?
Accompanying the massive growth in sensor data (from ubiquitous IoT devices, including location-based and time-based streaming data), there have emerged some special analytics products that are growing in significance, especially in the context of innovation and insights discovery from on-prem enterprise data sources. These enterprise analytics products are related to traditional predictive and prescriptive analytics, but these emergent products may specifically require low-latency (on-prem) data delivery to support enterprise requirements for timely, low-latency analytics product delivery. These three emergent analytics products are:
(a) Sentinel Analytics – focused on monitoring (“keeping an eye on”) multiple enterprise systems and business processes, as part of an observability strategy for time-critical business insights discovery and value creation from enterprise data sources. For example, sensors can monitor and “watch” systems and processes for emergent trends, patterns, anomalies, behaviors, and early warning signs that require interventions. Monitoring of data sources can include online web usage actions, streaming IT system patterns, system-generated log files, customer behaviors, environmental (ESG) factors, energy usage, supply chain, logistics, social and news trends, and social media sentiment. Observability represents the business strategy behind the monitoring activities. The strategy addresses the “what, when, where, why, and how” questions from business leaders concerning the placement of “sensors” that are used to collect the essential data that power the sentinel analytics product, in order to generate timely insights and thereby enable better data-informed “just in time” business decisions.
(b) Precursor Analytics – the use of AI and machine learning to identify, evaluate, and generate critical early-warning alerts in enterprise systems and business processes, using high-variety data sources to minimize false alarms (i.e., using high-dimensional data feature space to disambiguate events that seem to be similar, but are not). Precursor analytics is related to sentinel analytics. The latter is associated primarily with “watching” the data for interesting patterns, while precursor analytics is associated primarily with training the business systems to quickly identify those specific patterns and events that could be associated with high-risk events, thus requiring timely attention, intervention, and remediation. One could say that sentinel analytics is more like unsupervised machine learning, while precursor analytics is more like supervised machine learning. That is not a totally clear separation and distinction, but it might help to clarify their different applications of data science. Data scientists work with business users to define and learn the rules by which precursor analytics models produce high-accuracy early warnings. For example, an exploration of historical data may reveal that an increase in customer satisfaction (or dissatisfaction) with one particular product is correlated with some other satisfaction (or dissatisfaction) metric downstream at a later date. Consequently, based on this learning, deploying a precursor analytics product to detect the initial trigger event early can thus enable a timely response to the situation, which can produce a positive business outcome and prevent an otherwise certain negative outcome.
(c) Cognitive Analytics – focused on “surprise” discovery in diverse data streams across numerous enterprise systems and business processes, using machine learning and data science to emulate and automate the curiosity and cognitive abilities of humans – enabling the discovery of novel, interesting, unexpected, and potentially business-relevant signals across all enterprise data streams. These may not be high risk. They might actually be high-reward discoveries. For example, in one company, an employee noticed that it was the customer’s birthday during their interaction and offered a small gift to the customer at that moment—a gift that was pre-authorized by upper management because they understood that their employees are customer-facing and they anticipated that their employees would need to have the authority to take such customer-pleasing actions “in the moment”. The outcome was very positive indeed, as this customer reported the delightful experience on their social media account, thereby spreading positive sentiment about the business to a wide audience. Instead of relying on employees to catch all surprises in the data streams, the enterprise analytics applications can be trained to automatically watch for, identify, and act on these surprises. In the customer birthday example, the cognitive analytics product can be set up for automated detection and response, which can occur without the employee in the loop at all, such as in a customer’s online shopping experience or in a chat with the customer call center bot.
These three analytics products are derived from business value-driven data innovation and insights discovery in the enterprise. Investigating and deploying these are a worthy strategic move for any organization that is swimming in a sea (or lake or ocean) of on-prem enterprise data sources.
In closing, let us look at some non-enterprise examples of these three types of analytics:
Sentinel – the sentinel on the guard station at a military post is charged with watching for incoming activity. They are assigned this duty just in case something occurs during the night or when everyone else is busy with other operational things. That “something” might be an enemy approaching or a wild bear in the forest. In either case, keeping an eye on the situation is critical for the success of the operation. Another example of a sentinel is a marked increase in the volatility of stock market prices, indicating that there may be a lot of FUD (fear, uncertainty, and doubt) in the market that could lead to wild swings or downturns. In fact, anytime that any streaming data monitoring metric shows higher than usual volatility, this may be an indicator that the monitored thing requires some attention, an investigation, and possibly an intervention.
Precursor – prior to large earthquakes, it has been found that increased levels of radon are detected in soil, in groundwater, and even in the air in people’s home basements. This precursor is presumed to be caused by the radon being released from cavities within the Earth’s crust as the crust is being strained prior to the sudden slippage (the earthquake). Earthquakes themselves can be precursors to serious events – specifically, a large earthquake detected at the bottom of the ocean can produce a massive tidal wave, that can travel across the ocean and have drastic consequences on distant shores. In some cases, the precursor can occur sufficiently in advance of the tidal wave’s predicted arrival at inhabited shores, thereby enabling early warnings to be broadcasted. In both of these cases, the precursor (radon release or ocean-based earthquake) is not the biggest problem, though they may be seen as sentinels of an on-going event, but the precursor is an early warning sign of a potentially bigger catastrophe that’s coming (a major land-based earthquake or a tidal wave hitting major population centers along coastlines, respectively).
Cognitive – a cognitive person walking into an intense group meeting (perhaps a family or board meeting) can probably tell the mood of the room fairly quickly. The signals are there, though mostly contextual, thus probably missed by a cognitively impaired person. A cognitive person is curious about odd things that they see and hear—things or circumstances or behaviors that seem out of context, unusual, and surprising. The thing itself (or the data about the thing) may not be surprising (though it could be), but the context (the “metadata”, which is “other data about the primary data”) provides a signal that something needs attention here. Perhaps the simplest expression of being cognitive in this data-drenched world comes from a quote attributed to famous science writer Isaac Asimov: “The most exciting phrase to hear in science, the one that heralds new discoveries, is not ‘Eureka!’ (I found it!) but ‘That’s funny…‘.”
The cognitive enterprise versus the cognitively impaired enterprise – which of these would your organization prefer to be? Get moving now with sentinel, precursor, and cognitive analytics through data innovation and insights discovery with your on-prem enterprise data sources.
Read more about analytics innovation from on-prem enterprise data sources in this 3-part blog series:
We discussed in another article the key role of enterprise data infrastructure in enabling a culture of data democratization, data analytics at the speed of business questions, analytics innovation, and business value creation from those innovative data analytics solutions. Now, we drill down into some of the special characteristics of data and enterprise data infrastructure that ignite analytics innovation.
First, a little history – years ago, at the dawn of the big data age, there was frequent talk of the three V’s of big data (data’s three biggest challenges): volume, velocity, and variety. Though those discussions are now considered “ancient history” in the current AI-dominated era, the challenges have not vanished. In fact, they have grown in importance and impact.
While massive data volumes appear less frequently now in strategic discussions and are being tamed with excellent data infrastructure solutions from Pure Storage, the data velocity and data variety challenges remain in their own unique “sweet spot” of business data strategy conversations. We addressed the data velocity challenges and solutions in our previous article: “Solving the Data Daze – Analytics at the Speed of Business Questions”. We will now take a look at the data variety challenge, and then we will return to modern enterprise data infrastructure solutions for handling all big data challenges.
Okay, data variety—what is there about data variety that makes it such a big analytics challenge? This challenge often manifests itself when business executives ask a question like this: “what value and advantages will all that diversity in data sources, venues, platforms, modalities, and dimensions actually deliver for us in order to outweigh the immense challenges that high data variety brings to our enterprise data team?”
Because nearly all organizations collect many types of data from many different sources for many business use cases, applications, apps, and development activities, consequently nearly every organization is facing this dilemma.
Data is more than just another digital asset of the modern enterprise. It is an essential asset. And data is now a fundamental feature of any successful organization. Beyond the early days of data collection, where data was acquired primarily to measure what had happened (descriptive) or why something is happening (diagnostic), data collection now drives predictive models (forecasting the future) and prescriptive models (optimizing for “a better future”). Business leaders need more than backward-looking reports, though those are still required for some stakeholders and regulators. Leaders now require forward-looking insights for competitive market advantage and advancement.
So, what happens when the data flows are not quarterly, or monthly, or even daily, but streaming in real-time? The business challenges then become manifold: talent and technologies now must be harnessed, choreographed, and synchronized to keep up with the data flows that carry and encode essential insights flowing through business processes at light speed. Insights discovery (powered by analytics, data science, and machine learning) drives next-best decisions, next-best actions, and business process automation.
In the early days of the current data analytics revolution, one would often hear business owners say that they need their data to move at the speed of business. Well, it soon became clear that the real problem was the reverse: how can we have our business move at the speed of our data? Fortunately, countless innovative products and services in the data analytics world have helped organizations in that regard, through an explosion in innovation around data analytics, data science, data storytelling, data-driven decision support, talent development, automation, and AI (including the technologies associated with machine learning, deep learning, generative AI, and ChatGPT).
Artificial intelligence (AI) is top of mind for executives, business leaders, investors, and most workplace employees everywhere. The impacts are expected to be large, deep, and wide across the enterprise, to have both short-term and long-term effects, to have significant potential to be a force both for good and for bad, and to be a continuing concern for all conscientious workers. In confronting these winds of change, enterprise leaders are faced with many new questions, decisions, and requirements – including the big question: are these winds of change helping us to move our organization forward (tailwinds) or are they sources of friction in our organization (headwinds)?
The current AI atmosphere in enterprises reminds us of the internet’s first big entrance into enterprises nearly three decades ago. I’m not referring to the early days of email and Usenet newsgroups, but the tidal wave of Web and e-Commerce applications that burst onto the business scene in the mid-to-late 1990’s. While those technologies brought much value to the enterprise, they also brought an avalanche of IT security concerns into the C-suite, leading to more authoritative roles for the CIO and the CISO. The fraction of enterprise budgets assigned to these IT functions (especially cybersecurity) suddenly and dramatically increased. That had and continues to have a very big and long-lasting impact.
The Web/e-Commerce tidal wave also brought a lot of hype and FOMO, which ultimately led to the Internet bubble burst (the dot-com crash) in the early 2000’s. AI, particularly the new wave of generative AI applications, has the potential to repeat this story, potentially unleashing a wave of similar patterns in the enterprise. Are we heading for another round of hype / high hopes / exhilaration / FOMO / crash and burn with AI? I hope not.
I would like to believe that a sound, rational, well justified, and strategic introduction of the new AI technologies (including ChatGPT and other generative AI applications) into enterprises can offer a better balance on the fast slopes of technological change (i.e., protecting enterprise leaders from getting out too far over their skis). In our earlier article, we discussed “AI Readiness is Not an Option.” In this article here, we offer some considerations for enterprise AI to add to those strategic conversations. Specifically, we look at considerations from the perspective of the fuel for enterprise AI applications: the algorithms, the data, and the enterprise AI infrastructure. Here is my list:
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. The insights are used to produce informative content for stakeholders (decision-makers, business users, and clients). Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data.
We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry. With all the data in and around the enterprise, users would say that they have a lot of information but need more insights to assist them in producing better and more informative content. This is where we dispel an old “big data” notion (heard a decade ago) that was expressed like this: “we need our data to run at the speed of business.” Instead, what we really need is for our business to run at the speed of data. It is a major digital transformation challenge for businesses to keep up with data flows coming from a multitude of diverse sources, in different formats, at different cadences, on different dimensions of the enterprise, captured “safely” in different business silos. Transforming data to actionable insights and informative content needs some help!
AI is now helping in all these steps – not simply because it is “Artificial” intelligence, but primarily because AI is a tool for assisted, amplified, and augmented intelligence (the “new AI”) and because AI powers accelerated and automated intelligence, in order to deliver actionable intelligence. It appears that it’s AI everywhere all the time.
AI can help business users extract and produce (i.e., generate) informative content from insights. Plus, AI can also help find key insights encoded in data. And AI can help users find the appropriate data that they need from across the enterprise. In the language of Information Retrieval, AI delivers both high Recall (“did I get all the data that I need?”) and high Precision (“did I get only the data that I need?).
Discover the essential data – that’s AI.
Extract the essential insights from the data – that’s AI.
Produce essential content from the insights – that’s AI.
Well, okay, we can slap the “AI” label on everything, but what good is that? How are we helped when we board the AI hype train? In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies and business domain expertise at each step. This is where SAP Datasphere (the next generation of SAP Data Warehouse Cloud) comes in.
The new SAP Datasphere comprehensive data service provides powerful, seamless, and scalable access across the enterprise, across business departments, and across business silos to the specific mission-critical business data collection(s) that are needed for each unique business use case: access to external insights from data on the marketplace and competitors, access to internal insights from data on business processes and enterprise resources, and access to insights on customer-facing business products and services at the intersection of internal and external data sources.
So, if your business users don’t have access to the right data in the right context at the right time for the right business questions, then the whole business data workflow breaks down. SAP Datasphere has arrived to address those pain points, by enabling discovery, access, and integration of the heterogeneous data distributed across the enterprise. And so begins the process of insight discovery and content creation that meets the most significant, timely, and case-specific needs of decision-makers, business knowledge workers, and other stakeholders.
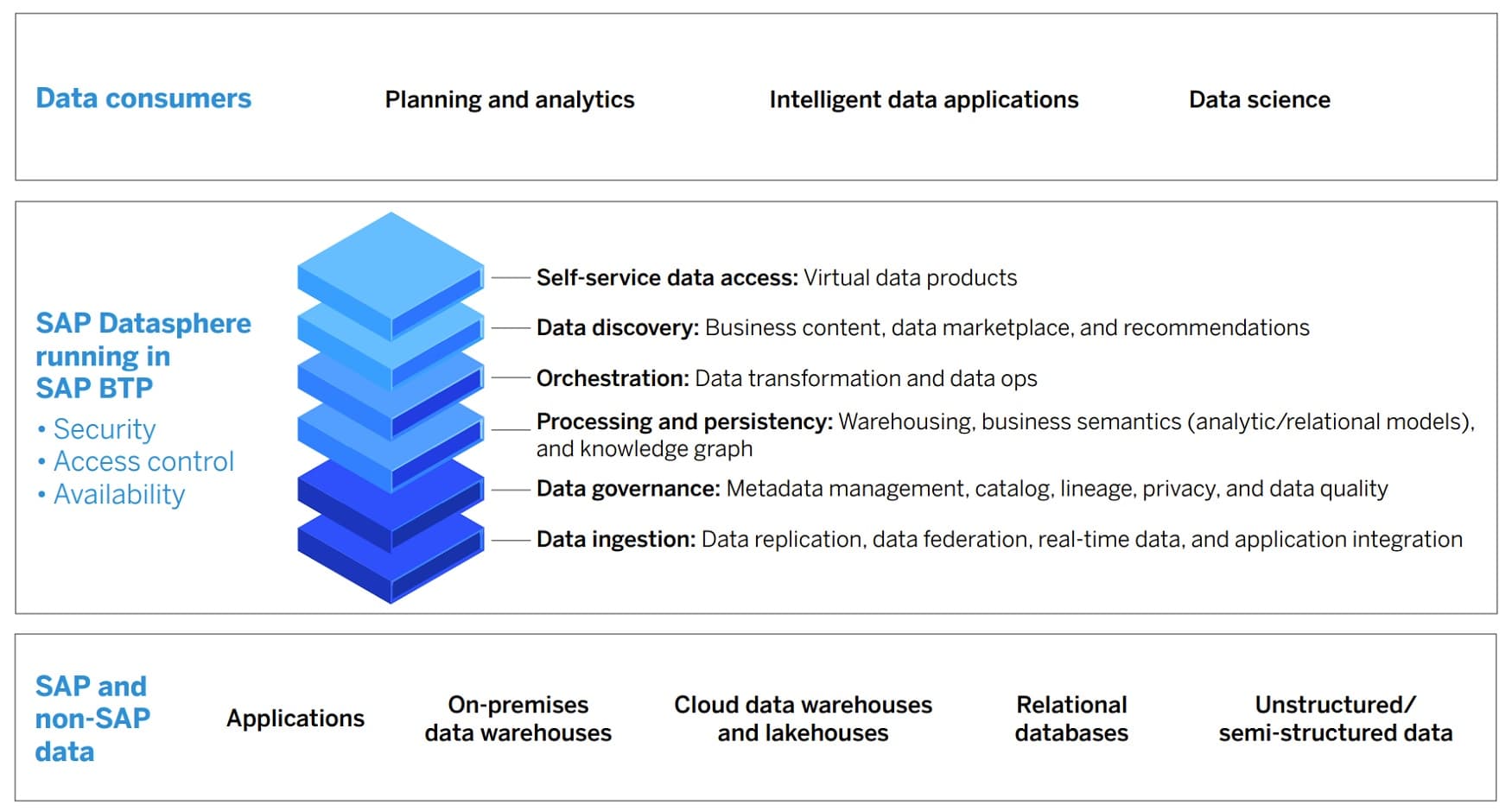
The release of SAP Datasphere was launched and announced globally on March 8, 2023. Live online presentations, demos, and customer testimonials were complemented with new content posted at sap.com/datasphere. Here are just 10 of the many key features of Datasphere that were covered during the launch day announcements:
Datasphere works with the SAP Analytics Cloud and runs on the existing SAP BTP (Business Technology Platform), with all the essential features: security, access control, high availability.
Datasphere accesses and integrates both SAP and non-SAP data sources into end-users’ data flows, including on-prem data warehouses, cloud data warehouses and lakehouses, relational databases, virtual data products, in-memory data, and applications that generate data (such as external API data loads).
Datasphere manages and integrates structured, semi-structured, and unstructured data types.
Datasphere empowers data democratization, by providing all business users with self-service data access, including virtual data products that can be stored, re-used, and shared.
Datasphere is a data discovery tool with essential functionalities: recommendations, data marketplace, and business content (i.e., incorporates the business context of the data and data products that are being recommended and delivered).
Datasphere goes beyond the “big three” data usage end-user requirements (ease of discovery, access, and delivery) to include data orchestration (data ops and data transformations) and business data contextualization (semantics, metadata, catalog services).
Datasphere is an enhanced data warehousing service that includes business semantics (through both analytic and relational models) and a knowledge graph (linking business content with business context).
Datasphere provides full-spectrum data governance: metadata management, data catalogs, data privacy, data quality, and data lineage (provenance) tracking.
Datasphere provides all the outgoing data orchestration functions and incoming data ingestion functions, including replication, federation, real-time stream processing, and application integration.
Datasphere is not just for data managers. It thrives with data consumers, who are doing planning, analytics, data science, and developing intelligent data applications – by providing those users with an end-to-end view of their data landscape in a trusted, secure, and actionable data environment.
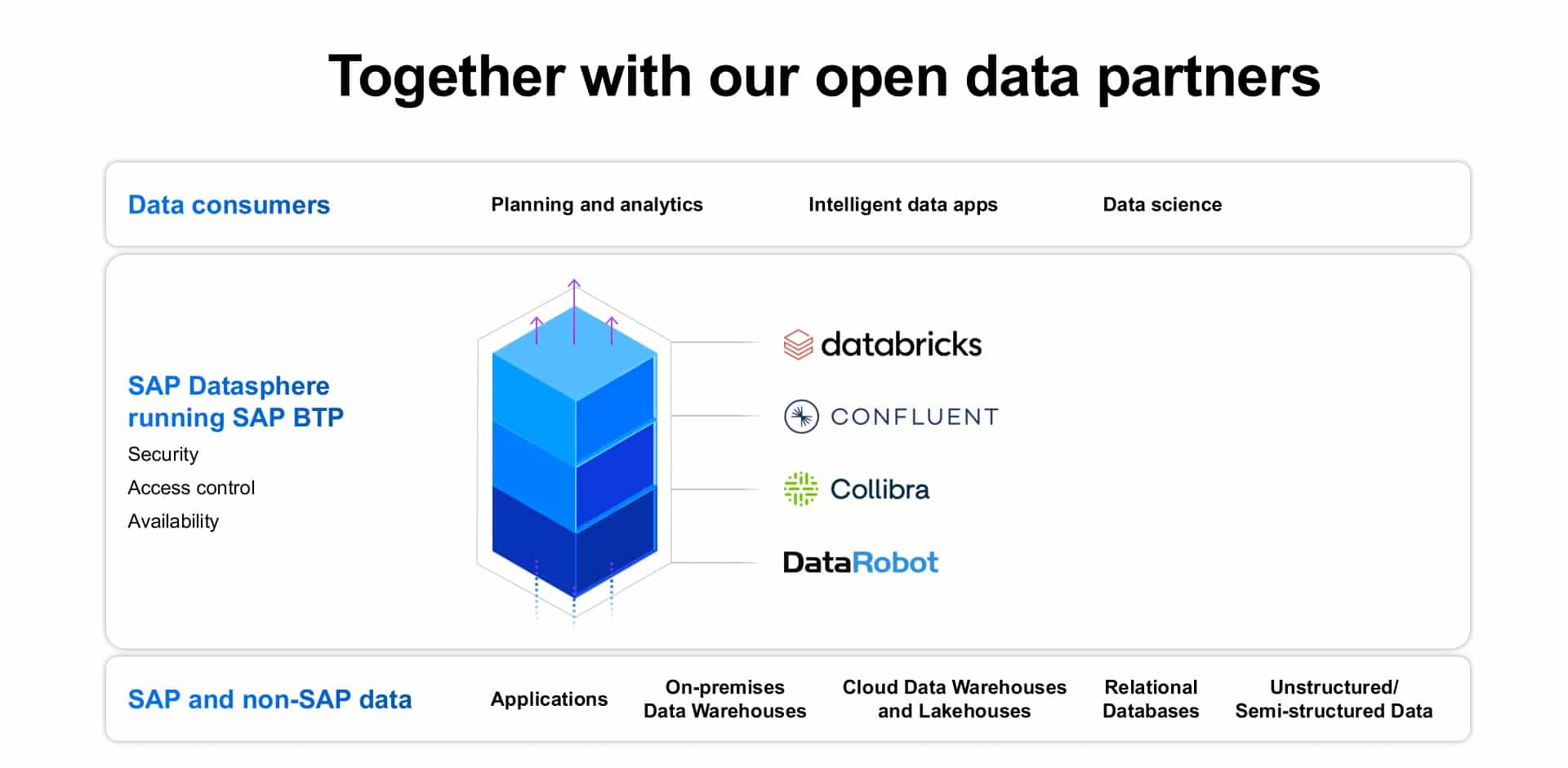
SAP also announced key partners that further enhance Datasphere as a powerful business data fabric. These partners are:
Collibra – providing data governance and discovery (metadata, catalogs) across the entire data landscape.
Confluent – providing access and discovery across real-time event data and streaming data. This emphatically addresses the “data in motion” challenge of enabling “business to run at the speed of data.”
Databricks – providing the complete business context across the evolved Data Warehouse Cloud – the new Data Lakehouse platform.
DataRobot – provides the AI, machine learning (ML), and AutoML capabilities that address the augmented intelligence requirements described at the beginning of this article.
I will finish with three quotes. The first is SAP customer testimonial from Mr. David Johnston, the Chief Information Officer at Messer Americas (leading provider of industrial and medical gases for over 120 years):
“The [Datasphere] business data fabric architecture enables us to bring SAP and non-SAP data together in the seamless and self-service way we’ve been envisioning. SAP Datasphere provided us with a solution to build a harmonized layer, or business data fabric, across SAP and non-SAP, cloud or on-premise data sources, making the best use of our existing investments [in both SAP and non-SAP data services].”
The second quote is from independent analyst Tony Baer:
“SAP’s goal is not simply pairing a data transformation factory with a data warehouse, but instead delivering a service that preserves the context of source data. As you would guess, maintaining context relies on metadata. The challenge is that when you use existing tools for replicating, moving and transforming data, the metadata typically does not usually go along with it. … SAP’s applications are a rich treasure store for business data and the process semantics that go with them. So, it’s logical that SAP has expanded on the business semantic layer of its Data Warehouse Cloud to deliver a data fabric that surfaces the metadata in business terms.”
The third quote is from Juergen Mueller, SAP Chief Technology Officer and member of the Executive Board of SAP SE:
“With SAP customers generating 87% of total global commerce, SAP data is among a company’s most valuable business assets and is contained in the most important functions of an organization, from manufacturing to supply chains, finance, human resources and more. We want to help our customers take the next step to easily and confidently integrate SAP data with non-SAP data from third-party applications and platforms, unlocking entirely new insights and knowledge to bring digital transformation to another level.”
Read, take a tour, try the free tier, deep dive, and learn more about SAP Datasphere here: