The year 2020 was remarkably different in many ways from previous years. In at least one way, it was not different, and that was in the continued development of innovations that are inspired by data. This steady march of data-driven innovation has been a consistent characteristic of each year for at least the past decade. These data-fueled innovations come in the form of new algorithms, new technologies, new applications, new concepts, and even some “old things made new again”.
I provide below my perspective on what was interesting, innovative, and influential in my watch list of the Top 10 data innovation trends during 2020.
1) Automated Narrative Text Generation tools became incredibly good in 2020, being able to create scary good “deep fake” articles. The GPT-3 (Generative Pretrained Transformer, 3rd generation text autocomplete) algorithm made headlines since it demonstrated that it can start with a very thin amount of input (a short topic description, or a question), from which it can then generate several paragraphs of narrative that are very hard (perhaps impossible) to distinguish from human-generated text. However, it is far from perfect, since it certainly does not have reasoning skills, and it also loses its “train of thought” after several paragraphs (e.g., by making contradictory statements at different places in the narrative, even though the statements are nicely formed sentences).
2) MLOps became the expected norm in machine learning and data science projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase. MLOps “done right” addresses sustainable model operations, explainability, trust, versioning, reproducibility, training updates, and governance (i.e., the monitoring of very important operational ML characteristics: data drift, concept drift, and model security).
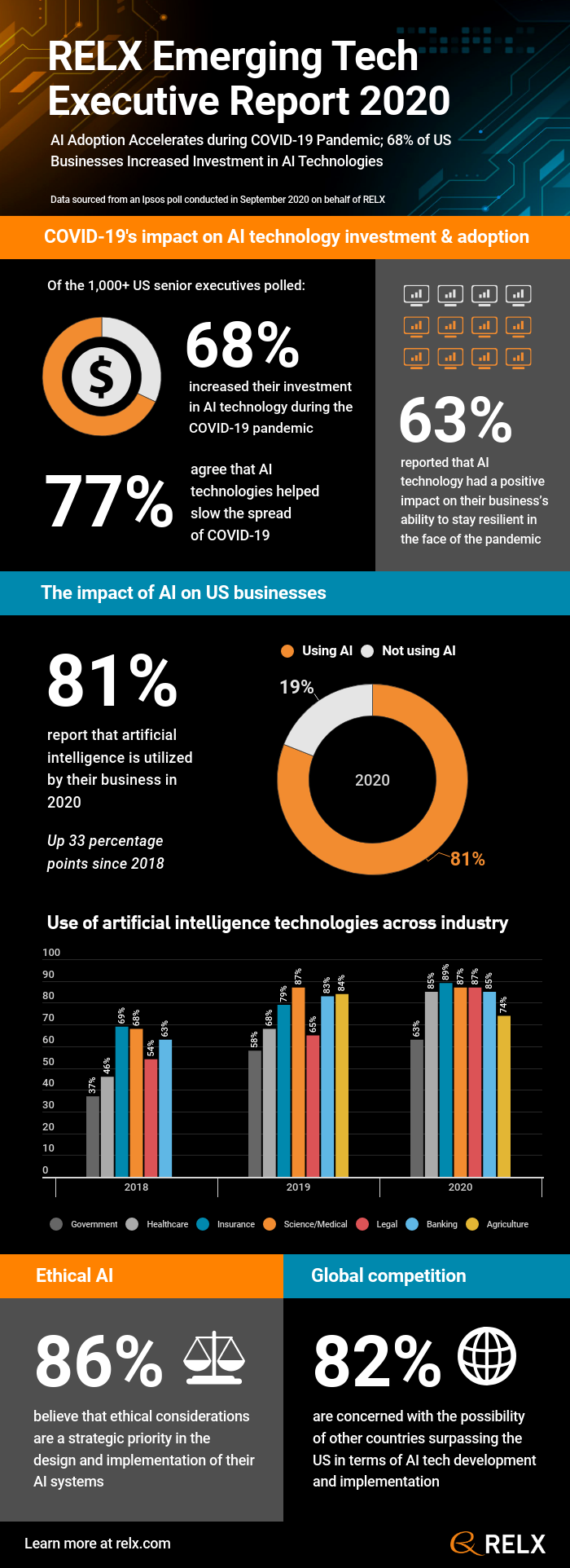
3) Concept drift by COVID – as mentioned above, concept drift is being addressed in machine learning and data science projects by MLOps, but concept drift is so much bigger than MLOps. Specifically, it feels to many of us like a decade of business transformation was compressed into the one year 2020. How and why businesses make decisions, customers make decisions, and anybody else makes decisions became conceptually and contextually different in 2020. Customer purchase patterns, supply chain, inventory, and logistics represent just a few domains where we saw new and emergent behaviors, responses, and outcomes represented in our data and in our predictive models. The old models were not able to predict very well based on the previous year’s data since the previous year seemed like 100 years ago in “data years”. Another example was in new data-driven cybersecurity practices introduced by the COVID pandemic, including behavior biometrics (or biometric analytics), which were driven strongly by the global “work from home” transition, where many insecurities in networks, data-sharing, and collaboration / communication tools were exposed. Behavior biometrics may possibly become the essential cyber requirement for unique user identification, finally putting weak passwords out of commission. Data and network access controls have similar user-based permissions when working from home as when working behind the firewall at your place of business, but the security checks and usage tracking can be more verifiable and certified with biometric analytics. This is critical in our massively data-sharing world and enterprises.
4) AIOps increasingly became a focus in AI strategy conversations. While it is similar to MLOps, AIOps is less focused on the ML algorithms and more focused on automation and AI applications in the enterprise IT environment – i.e., focused on operationalizing AI, including data orchestration, the AI platform, AI outcomes monitoring, and cybersecurity requirements. AIOps appears in discussions related to ITIM (IT infrastructure monitoring), SIEM (security information and event management), APM (application performance monitoring), UEBA (user and entity behavior analytics), DevSecOps, Anomaly Detection, Rout Cause Analysis, Alert Generation, and related enterprise IT applications.
5) The emergence of Edge-to-Cloud architectures clearly began pushing Industry 4.0 forward (with some folks now starting to envision what Industry 5.0 will look like). The Edge-to-Cloud architectures are responding to the growth of IoT sensors and devices everywhere, whose deployments are boosted by 5G capabilities that are now helping to significantly reduce data-to-action latency. In some cases, the analytics and intelligence must be computed and acted upon at the edge (Edge Computing, at the point of data collection), as in autonomous vehicles. In other cases, the analytics and insights may have more significant computation requirements and less strict latency requirements, thus allowing the data to be moved to larger computational resources in the cloud. The almost forgotten “orphan” in these architectures, Fog Computing (living between edge and cloud), is now moving to a more significant status in data and analytics architecture design.
6) Federated Machine Learning (FML) is another “orphan” concept (formerly called Distributed Data Mining a decade ago) that found new life in modeling requirements, algorithms, and applications in 2020. To some extent, the pandemic contributed to this because FML enforces data privacy by essentially removing data-sharing as a requirement for model-building across multiple datasets, multiple organizations, and multiple applications. FML model training is done incrementally and locally on the local dataset, with the meta-parameters of the local models then being shared with a centralized model-inference engine (which does not see any of the private data). The centralized ML engine then builds a global model, which is communicated back to the local nodes. Multiple iterations in parameter-updating and hyperparameter-tuning can occur between local nodes and the central inference engine, until satisfactory model performance is achieved. All through these training stages, data privacy is preserved, while allowing for the generation of globally useful, distributable, and accurate models.
7) Deep learning (DL) may not be “the one algorithm to dominate all others” after all. There was some research published earlier in 2020 that found that traditional, less complex algorithms can be nearly as good or better than deep learning on some tasks. This could be yet another demonstration of the “no free lunch theorem”, which basically states that there is no single universal algorithm that is the best for all problems. Consequently, the results of the new DL research may not be so surprising, but they certainly prompt us with necessary reminders that sometimes simple is better than complexity, and that the old saying is often still true: “perfect is the enemy of good enough.”
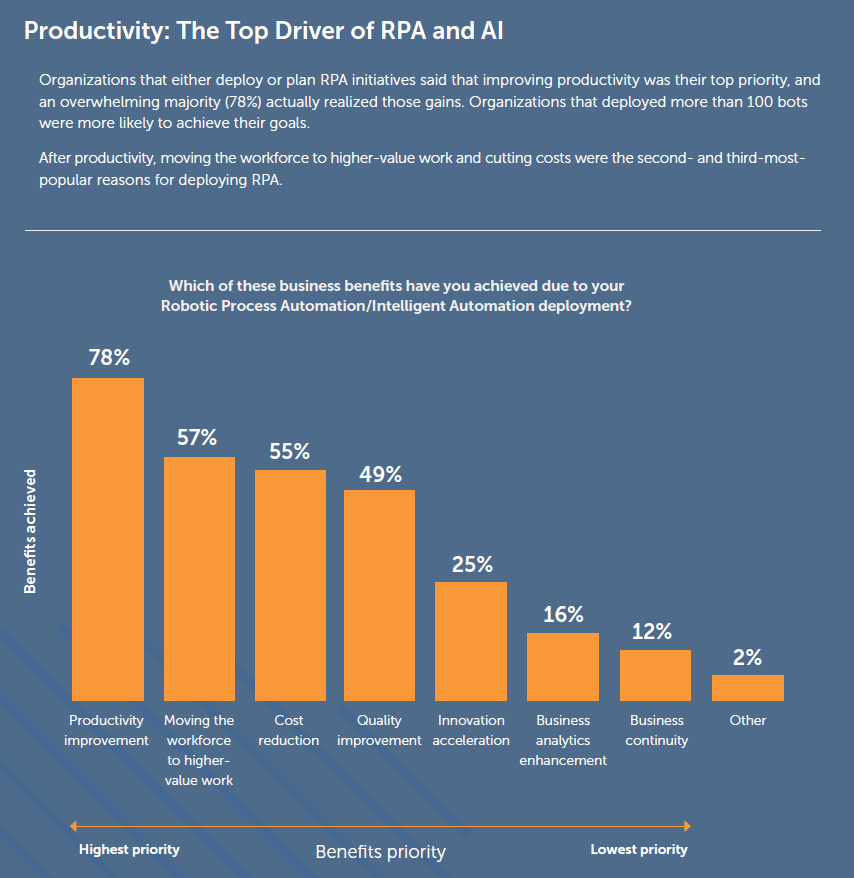
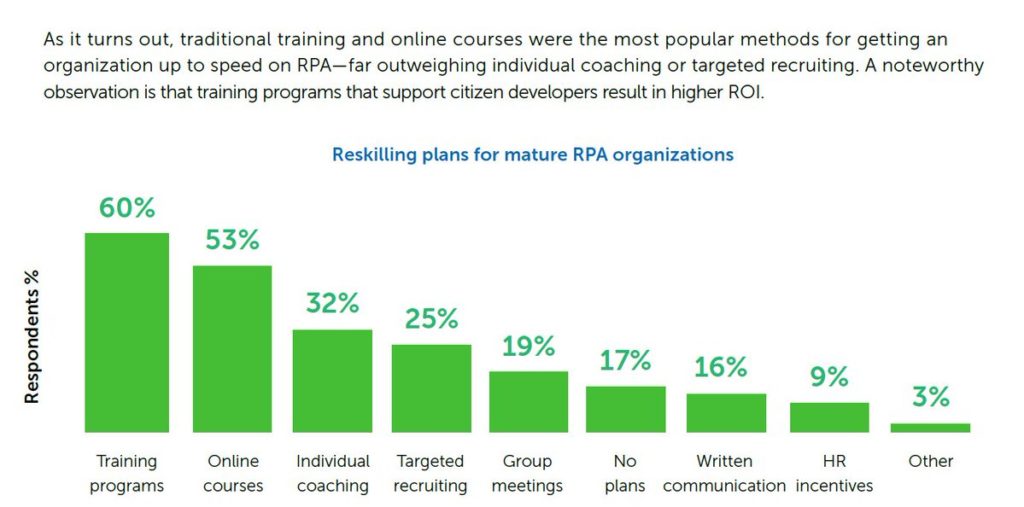
8) RPA (Robotic Process Automation) and intelligent automation were not new in 2020, but the surge in their use and in the number of providers was remarkable. While RPA is more rule-based (informed by business process mining, to automate work tasks that have very little variation), intelligent automation is more data-driven, adaptable, and self-learning in real-time. RPA mimics human actions, by repetition of routine tasks based on a set of rules. Intelligent automation simulates human intelligence, which responds and adapts to emergent patterns in new data, and which is capable of learning to automate non-routine tasks. Keep an eye on the intelligent automation space for new and exciting developments to come in the near future around hyperautomation and enterprise intelligence, such as the emergence of learning business systems that learn and adapt their processes based on signals in enterprise data across numerous business functions: finance, marketing, HR, customer service, production, operations, sales, and management.
9) The Rise of Data Literacy initiatives, imperatives, instructional programs, and institutional awareness in 2020 was one of the two most exciting things that I witnessed during the year. (The other one of the two is next on my list.) I have said for nearly 20 years that data literacy must become a key component of education at all levels and an aptitude of nearly all employees in all organizations. The world is data, revolves around data, produces and consumes massive quantities of data, and drives innovative emerging technologies that are inspired by, informed by, and fueled by data: augmented reality (AR), virtual reality (VR), autonomous vehicles, computer vision, digital twins, drones, robotics, AI, IoT, hyperautomation, virtual assistants, conversational AI, chatbots, natural language understanding and generation (NLU, NLG), automatic language translation, 4D-printing, cyber resilience, and more. Data literacy is essential for future of work, future innovation, work from home, and everyone that touches digital information. Studies have shown that organizations that are not adopting data literacy programs are not only falling behind, but they may stay behind, their competition. Get on board with data literacy! Now!
10) Observability emerged as one of the hottest and (for me) most exciting developments of the year. Do not confuse observability with monitoring (specifically, with IT monitoring). The key difference is this: monitoring is what you do, and observability is why you do it. Observability is a business strategy: what you monitor, why you monitor it, what you intend to learn from it, how it will be used, and how it will contribute to business objectives and mission success. But the power, value, and imperative of observability does not stop there. Observability meets AI – it is part of the complete AIOps package: “keeping an eye on the AI.” Observability delivers actionable insights, context-enriched data sets, early warning alert generation, root cause visibility, active performance monitoring, predictive and prescriptive incident management, real-time operational deviation detection (6-Sigma never had it so good!), tight coupling of cyber-physical systems, digital twinning of almost anything in the enterprise, and more. And the goodness doesn’t stop there. The emergence of standards, like OpenTelemetry, can unify all aspects of your enterprise observability strategy: process instrumentation, sensing, metrics specification, context generation, data collection, data export, and data analysis of business process performance and behavior monitoring in the cloud. This plethora of benefits is a real game-changer for open-source self-service intelligent data-driven business process monitoring (BPM) and application performance monitoring (APM), feedback, and improvement. As mentioned above, monitoring is “what you are doing”, and observability is “why you are doing it.” If your organization is not having “the talk” about observability, now is the time to start – to understand why and how to produce business value through observability into the multitude of data-rich digital business applications and processes all across the modern enterprise. Don’t drown in those deep seas of data. Instead, develop an Observability Strategy to help your organization ride the waves of data, to help your business innovation and transformation practices move at the speed of data.
In summary, my top 10 data innovation trends from 2020 are:
- GPT-3
- MLOps
- Concept Drift by COVID
- AIOps
- Edge-to-Cloud and Fog Computing
- Federated Machine Learning
- Deep Learning meets the “no free lunch theorem”
- RPA and Intelligent Automation
- Rise of Data Literacy
- Observability
If I were to choose what was hottest trend in 2020, it would not be a single item in this top 10 list. The hottest trend would be a hybrid (convergence) of several of these items. That hybrid would include: Observability, coupled with Edge and the ever-rising ubiquitous IoT (sensors on everything), boosted by 5G and cloud technologies, fueling ever-improving ML and DL algorithms, all of which are enabling “just-in-time” intelligence and intelligent automation (for data-driven decisions and action, at the point of data collection), deployed with a data-literate workforce, in a sustainable and trusted MLOps environment, where algorithms, data, and applications work harmoniously and are governed and secured by AIOps.
If we learned anything from the year 2020, it should be that trendy technologies do not comprise a menu of digital transformation solutions to choose from, but there really is only one combined solution, which is the hybrid convergence of data innovation technologies. From my perspective, that was the single most significant data innovation trend of the year 2020.