I have written articles in many places. I will be collecting links to those sources here. The list is not complete and will be constantly evolving. There are some older blogs that I will be including in the list below as I remember them and find them. Also included are some interviews in which I provided detailed answers to a variety of questions.
And then there’s this — not a blog, but a link to my 2013 TedX talk: “Big Data, Small World.” (Many more videos of my talks are available online. That list will be compiled in another place soon.)
Definitions of terminology frequently seen and used in discussions of emerging digital technologies.
Additive Manufacturing: see 3D-Printing
AGI (Artificial General Intelligence): The intelligence of a machine that has the capacity to understand or learn any intellectual task that a human being can. It is a primary goal of some artificial intelligence research and a common topic in science fiction and future studies.
AI (Artificial Intelligence): Application of Machine Learning algorithms to robotics and machines (including bots), focused on taking actions based on sensory inputs (data). Examples: (1-3) All those applications shown in the definition of Machine Learning. (4) Credit Card Fraud Alerts. (5) Chatbots (Conversational AI). There is nothing “artificial” about the applications of AI, whose tangible benefits include Accelerated Intelligence, Actionable Intelligence (and Actionable Insights), Adaptable Intelligence, Amplified Intelligence, Applied Intelligence, Assisted Intelligence, and Augmented Intelligence.
Algorithm: A set of rules to follow to solve a problem or to decide on a particular action (e.g., the thermostat in your house, or your car engine alert light, or a disease diagnosis, or the compound interest growth formula, or assigning the final course grade for a student).
Analytics: The products of Machine Learning and Data Science (such as predictive analytics, health analytics, cyber analytics).
AR (Augmented Reality): A technology that superimposes a computer-generated image on a user’s view of the real world, thus providing a composite view. Examples: (1) Retail. (2) Disaster Response. (3) Machine maintenance. (4) Medical procedures. (5) Video games in your real world. (6) Clothes shopping & fitting (seeing the clothes on you without a dressing room). (7) Security (airports, shopping malls, entertainment & sport events).
Autonomous Vehicles: Self-driving (guided without a human), informed by data streaming from many sensors (cameras, radar, LIDAR), and makes decisions and actions based on computer vision algorithms (ML and AI models for people, things, traffic signs,…). Examples: Cars, Trucks, Taxis
BI (Business Intelligence): Technologies, applications and practices for the collection, integration, analysis, and presentation of business information. The purpose of Business Intelligence is to support better business decision-making.
Big Data: An expression that refers to the current era in which nearly everything is now being quantified and tracked (i.e., data-fied). This leads to the collection of data and information on nearly full-population samples of things, instead of “representative subsamples”. There have been many descriptions of the characteristics of “Big Data”, but the three dominant attributes are Volume, Velocity, and Variety — the “3 V’s” concept was first introduced by Doug Laney in 2001 here. Read more in this article: “Why Today’s Big Data is Not Yesterday’s Big Data“. Some consider the 2011 McKinsey & Company research report “Big Data: The Next Frontier for Innovation, Competition, and Productivity” as the trigger point when the world really started paying attention to the the volume and variety of data that organizations everywhere are collecting — the report stated, “The United States alone could face a shortage of 140,000 to 190,000 people with deep analytical skills as well as 1.5 million managers and analysts with the know-how to use the analysis of big data to make effective decisions.”
Blockchain: A system in which a permanent and verifiable record of transactions is maintained across several computers that are linked in a peer-to-peer network. It has many applications beyond its original uses for bitcoin and other cryptocurrencies. Blockchain in an example of Distributed Ledger Technology, in which independent computers (referred to as nodes) record, share and synchronize transactions in their respective electronic ledgers (instead of keeping data centralized as in a traditional ledger). Blockchain’s name refers to a chain (growing list) of records, called blocks, which are linked using cryptography, and are used to record transactions between two parties efficiently and in a verifiable and permanent way. In simplest terms, Blockchain is a distributed database existing on multiple computers at the same time. It grows as new sets of recordings, or ‘blocks’, are added to it, forming a chain. The database is not managed by any particular body; instead, everyone in the network gets a copy of the whole database. Old blocks are preserved forever and new blocks are added to the ledger irreversibly, making it impossible to manipulate by faking documents, transactions and other information. All blocks are encrypted in a special way, so everyone can have access to all the information but only a user who owns a special cryptographic key is able to add a new record to a particular chain.
Chatbots (see also Virtual Assistants): These typically are text-based user interfaces (often customer-facing for organizations) that are designed and programmed to reply to only a certain set of questions or statements. If the question asked is other than the learned set of responses by the customer, the chatbot will fail. Chatbots cannot hold long, continuing human interaction. Traditionally they are text-based but audio and pictures can also be used for interaction. They provide more like an FAQ (Frequently Asked Questions) type of an interaction. They cannot process language inputs generally.
Cloud: The cloud is a metaphor for a global network of remote servers that operates transparently to the user as a single computing ecosystem, commonly associated with Internet-based computing.
Cloud Computing: The practice of using a network of remote servers hosted on the Internet to store, manage, and process data, rather than a local server, local mainframe, or a personal computer.
Computer Vision: An interdisciplinary scientific field that focuses on how computers can be made to gain high-level understanding from digital images or videos. From the perspective of engineering, it seeks to automate tasks that the human visual system can do, including pattern detection, pattern recognition, pattern interpretation, and pattern classification.
Data Mining: Application of Machine Learning algorithms to large data collections, focused on pattern discovery and knowledge discovery in data. Pattern discovery includes clusters (class discovery), correlation (and trend) discovery, link (association) discovery, and anomaly detection (outlier detection, surprise discovery).
Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more).
Digital Transformation: Refers to the novel use of digital technology to solve traditional problems. These digital solutions enable — other than efficiency via automation — new types of innovation and creativity, rather than simply enhance and support traditional methods.
Digital Twins: A phrase used to describe a computerized (or digital) version of a real physical asset and/or process. The digital twin contains one or more sensors that collects data to represent real-time information about the physical asset. By bridging the physical and the virtual world, data is transmitted seamlessly allowing the virtual entity to exist simultaneously with the physical entity. Digital Twins are used in manufacturing, large-scale systems (such as maritime vessels, wind farms, space probes) and other complex systems. Digital Twins are virtual replicas of physical devices that data scientists and IT pros can use to run simulations before actual devices are built and deployed, and also while those devices are in operation. They represent a strong merging and optimization of numerous digital technologies such as IoT (IIoT), AI, Machine Learning, and Big Data Analytics.
Drone (UAV, UAS): An unmanned aerial vehicle (UAV) or uncrewed aerial vehicle (commonly known as a Drone) is an aircraft without a human pilot on board. UAVs are a component of an unmanned aircraft system (UAS); which include a UAV, a ground-based controller, and a system of communications between the two.
Dynamic Data-driven Application (Autonomous) Systems (DDDAS): A paradigm in which the computation and instrumentation aspects of an application system are dynamically integrated in a feed-back control loop, such that instrumentation data can be dynamically incorporated into the executing model of the application, and in reverse the executing model can control the instrumentation. Such approaches can enable more accurate and faster modeling and analysis of the characteristics and behaviors of a system and can exploit data in intelligent ways to convert them to new capabilities, including decision support systems with the accuracy of full scale modeling, efficient data collection, management, and data mining. See http://dddas.org/.
Edge Computing (and Edge Analytics): A distributed computing paradigm which brings computation to the data, closer to the location where it is needed, to improve response times in autonomous systems and to save bandwidth. Edge Analytics specifically refers to an approach to data collection and analysis in which an automated analytical computation is performed on data at a sensor, network switch or other device instead of waiting for the data to be sent back to a centralized data store. This is important in applications where the result of the analytic computation is needed as fast as possible (at the point of data collection), such as in autonomous vehicles or in digital manufacturing.
Industry 4.0: A reference to a new phase in the Industrial Revolution that focuses heavily on interconnectivity, automation, Machine Learning, and real-time data. Industry 4.0 is also sometimes referred to as IIoT (Industrial Internet of Things) or Smart Manufacturing, because it joins physical production and operations with smart digital technology, Machine Learning, and Big Data to create a more holistic and better connected ecosystem for companies that focus on manufacturing and supply chain management.
IoT (Internet of Things) and IIoT (Industrial IoT): Sensors embedded on devices and within things everywhere, measuring properties of things, and sharing that data over the Internet (over fast 5G), to fuel ML models and AI applications (including AR and VR) and to inform actions (robotics, autonomous vehicles, etc.). Examples: (1) Wearable health devices (Fitbit). (2) Connected cars. (3) Connected products. (4) Precision farming. (5) Industry 4.0
Knowledge Graphs (see also Linked Data): Knowledge graphs encode knowledge arranged in a network of nodes (entities) and links (edges) rather than tables of rows and columns. The graph can be used to link units of data (the nodes, including concepts and content), with a link (the edge) that explicitly specifies what type of relationship connects the nodes.
Linked Data (see also Knowledge Graphs): A data structure in which data items are interlinked with other data items that enables the entire data set to be more useful through semantic queries. The easiest and most powerful standard designed for Linked Data is RDF (Resource Description Framework).
Machine Learning (ML): Mathematical algorithms that learn from experience (i.e., pattern detection and pattern recognition in data). Examples: (1) Digit detection algorithm (used in automated Zip Code readers at Post Office. (2) Email Spam detection algorithm (used for Spam filtering). (3) Cancer detection algorithm (used in medical imaging diagnosis).
MR (Mixed Reality): Sometimes referred to as hybrid reality, is the merging of real and virtual worlds to produce new environments and visualizations where physical and digital objects co-exist and interact in real time. It means placing new imagery within a real space in such a way that the new imagery is able to interact, to an extent, with what is real in the physical world we know. The key characteristic of MR is that the synthetic content and the real-world content are able to react to each other in real time.
NLP (Natural Language Processing), NLG (NL Generation), NLU (NL Understanding): NLP a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human languages, in particular how to program computers to process and analyze large amounts of natural language data. NLG is a software process that transforms structured data into human-language content. It can be used to produce long form content for organizations to automate custom reports, as well as produce custom content for a web or mobile application, or produce the words that will be spoken by a Virtual (Voice-based) Assistant. NLU is a subtopic of Natural Language Processing in Artificial Intelligence that deals with algorithms that have language comprehension (understanding the meaning of the words, both their content and their context).
Quantum Computing: The area of study focused on developing computer technology based on the principles of quantum theory and quantum phenomena (such as superposition of states and entanglement). Qubits are the fundamental units of quantum computing — they are somewhat analogous to bits in a classical computer.
Robotics: A branch of AI concerned with creating devices that can move and react to sensory input (data). Examples: (1) Automated manufacturing assembly line. (2) Roomba (vacuums your house). (3) Warehouse / Logistics. (4) Prosthetics.
Statistics: the practice or science of collecting and analyzing numerical data, especially for the purpose of inferring proportions in a whole population from measurements of those properties within a representative subsample.
UAV (Unmanned Aerial Vehicle) and UAS (Unmanned Aircraft System): see Drones.
Virtual Assistants (see also Chatbots): A sophisticated voice-based interface in an interactive platform for user and customer interactions. Virtual assistants understand not only the language but also the meaning of what the user is saying. They can learn from their conversation instances, which can lead to an unpredictability in their behavior. Consequently, they can have extended adaptable human interaction. They can be set to perform slightly complicated tasks as well, such as order-taking and task fulfillment.
VR (Virtual Reality): Computer-generated simulation of a three-dimensional environment that can be interacted with in a seemingly real or physical way by a person using special electronic equipment, such as a helmet with a screen inside or gloves fitted with sensors. Examples: (1) Games. (2) Family adventures. (3) Training & Education. (4) Design. (5) Big Data Exploration.
XAI (eXplainable AI, Trusted AI): Artificial intelligence that is programmed to describe (explain) its purpose, rationale and decision-making process in a way that can be understood by the average person. This includes the specific criteria the program uses to arrive at a decision.
XPU: One of the many specialized CPUs for specific applications (similar to an ASIC), which may be real-time, data-intensive, data-specific, or at the edge (see Edge Analytics). For more information, refer to the article “Sensor Analytics at Micro Scale on the xPU“.
3D-Printing … moving on to 4D-printing: Additive Manufacturing — the action or process of making a physical object from a three-dimensional digital model, typically by laying down many thin layers of a material in succession. The terms “additive manufacturing” and “3D printing” both refer to creating an object by sequentially adding build material in successive cross-sections, one stacked upon another.
5G: Fifth-generation wireless, the latest iteration of cellular technology, engineered to greatly increase the speed and responsiveness of wireless networks. 5G will also enable a sharp increase in the amount of data transmitted over wireless systems due to more available bandwidth. Example applications: (1) High-definition and 3D video. (2) Gbit/sec Internet. (3) Broadband network access nearly everywhere. (4) IoT.
Diversity in data is one of the three defining characteristics of big data — high data variety — along with high data volume and high velocity. We discussed the power and value of high-variety data in a previous article: “The Five Important D’s of Big Data Variety” We won’t repeat those lessons here, but we focus specifically on the bias-busting power of high-variety data, which was actually the last of the five D’s mentioned in the earlier article: Decreased model bias.
Here, we broaden our meaning of “bias” to go beyond model bias, which has the technical statistical meaning of “underfitting”, which essentially means that there is more information and structure in the data than our model has captured. In the current context, we apply a broader definition of bias: lacking a neutral viewpoint, or having a viewpoint that is partial. We will call this natural bias, since the examples can be considered as “naturally occurring” without obvious intent. This article does not elaborate on personal bias (which might be intentional), though the cause for that kind of prejudice is essentially the same: not considering and taking into account the full knowledge and understanding of the person or entity that is the subject of the bias.
In that full version of this article, we go on to describe several examples of natural bias and then to present a recommended bias-busting remedy for those of us working in the realm of data science. We refer to that remedy as the CCDI data & analytics strategy: Collect, Curate, Differentiate, and Innovate.
Here is one of the four examples of natural bias that you will find in the longer, complete version of the article:
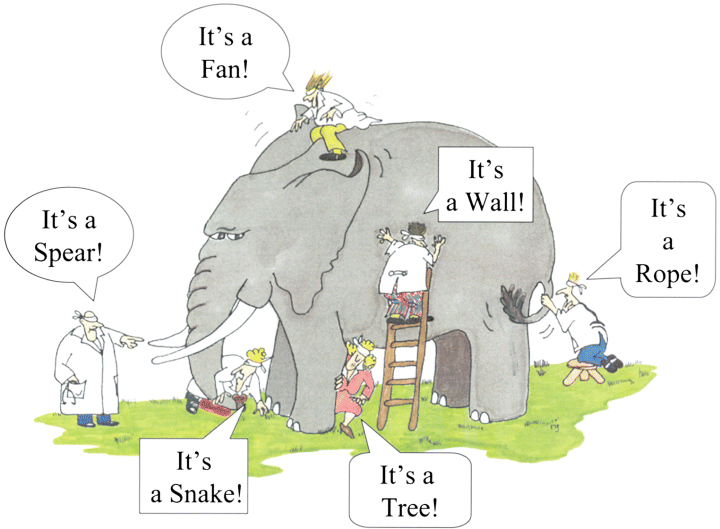
An example of natural bias comes from a famous cartoon. The cartoon shows three or more blind men (or blindfolded men) feeling an elephant. They each feel a different aspect of the elephant: the tail, a tusk, an ear, the body, a leg — and consequently they each offer a different interpretation of what they believe this thing is (which they cannot see). They say it might be a rope (the tail), or a spear (the tusk), or a large fan (the ear), or a wall (the body), or a tree trunk (the leg). Only after the blindfolds are removed (or an explanation is given) do they finally “see” the full truth of this large complex reality. It has many different features, facets, and characteristics. Focusing on only one of those features and insisting that this partial view describes the whole thing would be foolish. We have similar complex systems in our organizations, whether it is the human body (in healthcare), or our population of customers (in marketing), or the Earth (in climate science), or different components in a complex system (like a manufacturing facility), or our students (in a classroom), or whatever. Unless we break down the silos and start sharing our data (insights) about all the dimensions, viewpoints, and perspectives of our complex system, we will consequently be drawn into biased conclusions and actions, and thus miss the key insights that enable us to understand the wonderful complexity and diversity of the thing in its entirety. Integrating the many data sources enables us to arrive at the “single correct view” of the thing: the 360 view!
Collecting high-variety data from diverse sources, connecting the dots, and building the 360 view of our domain is not only the data silo-busting thing to do. It is also the bias-busting thing to do. High-variety data makes that possible, and there is no shortage of biases for high-variety data to bust, including cognitive bias, confirmation bias, salience bias, and sampling bias, just to name a few! …
(UPDATE – April 8, 2021) See this excellent new book by Jordan Morrow: “Be Data Literate: The Data Literacy Skills Everyone Needs To Succeed”, available at http://amzn.to/3rdWfsn
Be Data Literate: The Data Literacy Skills Everyone Needs to Succeed
One of the most important roles that we should be embracing right now is training the next-generation workforce in the art and science of data. Data Literacy is a fundamental literacy that should be imparted at the earliest levels of learning, and it should continue through all years of education. Education research has shown the value of using data in the classroom to teach any subject — so, I am not advocating the teaching of hard-core data science to children, but I definitely promote the use of data mining and data science applications in the teaching of other subjects (perhaps, in all subjects!). See my “Using Data in the Classroom Reading List” here on this subject. See also the book “Data Literacy – A User’s Guide” and this book:
I encourage you to read a position paper that I wrote (along with a few astronomy colleagues) for the US National Academies of Science in 2009 that addressed the data science literacy requirements in astronomy. Though focused on the needs in astronomy workforce development for the coming decade, the paper also contains more general discussion of “data literacy for the masses” that is applicable to any and all disciplines, domains, and organizations: “Data Science For The Masses.”