I recently attended the Splunk .conf23 conference in Las Vegas. Well, the conference was in Vegas, while I was far away in my home office watching the live conference keynote sessions online. Despite the thousands of miles (and kilometers) of separation, I could feel the excitement in the room as numerous announcements were made, individuals were honored, customer success stories were presented, and new solutions and product features were revealed. I will summarize many of those here (specifically my major learning moments), though this report cannot provide a complete review of all that was said at .conf23, primarily because I attended only the two main keynote sessions, but also because the phenomenal number of remarkable things to hear and learn in those sessions exceeded my capacity to record them all in one succinct report.
When I reviewed highlights from last year’s Splunk .conf22 conference in my summary report at that time, I focused a lot on the Splunk Observability Cloud and its incredible suite of Observability and Monitoring products and services. This reflected my strong interest in observability at that time. My strong interest hasn’t diminished, and neither has Splunk’s developments and product releases in that space, as seen in observability’s prominent mention within many of Splunk’s announcements at this year’s .conf23 event. For a detailed report on the current state of observability this year, you can access and download “The State of Observability 2023” report from Splunk. Here are four specific metrics from the report, highlighting the potentially huge enterprise system benefits coming from implementing Splunk’s observability and monitoring products and services:
- Four times as many leaders who implement observability strategies resolve unplanned downtime in just minutes, not hours or days.
- Leaders report one-third the number of outages per year, on average, compared to those organizations who do not implement observability and monitoring.
- Leaders are 7.9x as likely to say that their ROI on observability tools far exceeded expectations.
- 89% of leaders are completely confident in their ability to meet their application availability and performance requirements, versus just 43% of others.
Here are my top learnings from .conf23:
- Splunk announced a new strategic partnership with Microsoft Azure, thereby adding another major cloud provider to their other cloud provider partnerships, bringing Splunk products and services into more enterprises through the Azure Marketplace. This partnership also specifically extends hybrid cloud capabilities that will enhance organizations’ digital resilience, while enabling transformation, modernization, migration, and growth in all enterprise digital systems with confidence, trust, and security.
- Digital resilience was a major common theme across all of the Splunk announcements this week. As I heard someone say in the keynote session, “You had me at resilience!” By providing real-time data insights into all aspects of business and IT operations, Splunk’s comprehensive visibility and observability offerings enhance digital resilience across the full enterprise. Organizations are able to monitor integrity, quality drift, performance trends, real-time demand, SLA (service level agreement) compliance metrics, and anomalous behaviors (in devices, applications, and networks) to provide timely alerting, early warnings, and other confidence measures. From these data streams, real-time actionable insights can feed decision-making and risk mitigations at the moment of need. Such prescriptive capabilities can be more proactive, automated, and optimized, making digital resilience an objective fact for businesses, not just a business objective. I call that “digital resilience for the win!”
- Several Splunk customer success stories were presented, with interesting details of their enterprise systems, the “back stories” that led them to Splunk, the transformations that have occurred since Splunk integration, and the metrics to back up the success stories. Customers presenting at .conf23 included FedEx, Carnival Corporation & plc, Inter IKEA, and VMware. Here are a few of the customer performance metrics presented (measuring performance changes following the Splunk integration into the customers’ enterprise systems): 3X Faster Response Time, 90% Faster Mean Time to Remediation, and 60X Faster Insights.
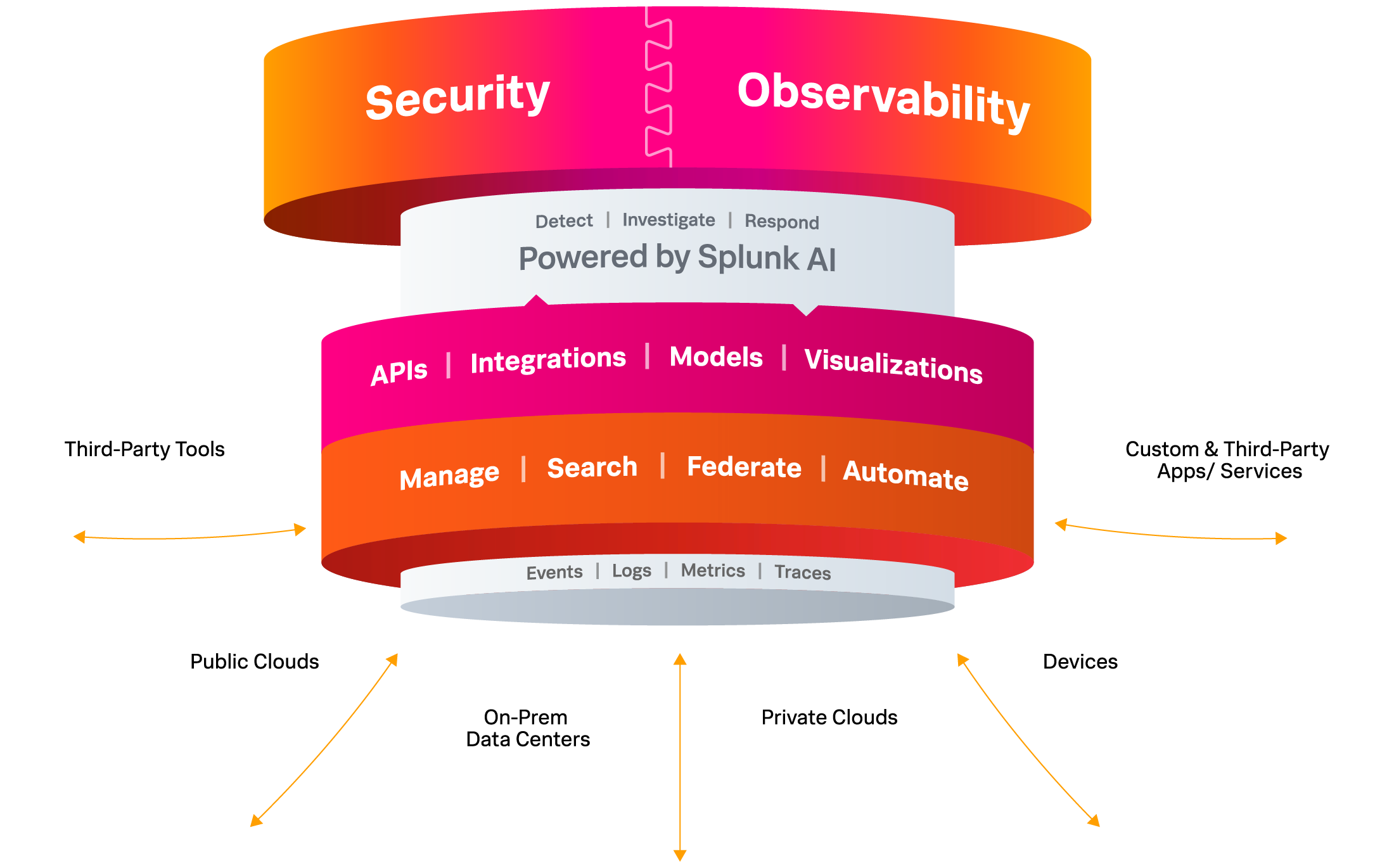
- Splunk has brought greater integration and customer ease-of-use of their offerings through a Unified Security and Observability Platform. This unified operations center (Splunk Mission Control) amplifies the efficiency (time to problem resolution) and effectiveness (number of time-critical problems resolved) of ITOps and DevOps teams, requiring fewer manual steps in correlating data streams from multiple systems in order to determine the root cause of an incident. Further enhancing the user experience, the unified platform provides end-to-end enterprise systems visibility and federated search across those systems.
- Splunk Mission Control (just mentioned above) – Splunk describes it best: “Splunk Mission Control brings together Splunk’s industry-leading security technologies that help customers take control of their detection, investigation and response processes. Splunk’s security offerings include security analytics (Splunk Enterprise Security), automation and orchestration (Splunk SOAR), and threat intelligence capabilities. In addition, Splunk Mission Control offers simplified security workflows with processes codified into response templates. With Splunk Mission Control, security teams can focus on mission-critical objectives, and adopt more proactive, nimble security operations.”
- Model-Assisted Threat Hunts, also known as Splunk M-ATH, is Splunk’s brand name for machine learning-assisted threat hunting and mitigation. M-ATH is part of the PEAK (Prepare, Execute, and Act with Knowledge) Framework, that consists of three types of hunts: (1) Hypothesis-driven (i.e., testing for hypothesized threats, behaviors, and activities), (2) Baseline (i.e., search for deviations from normal behaviors through EDA: Exploratory Data Analysis), and (3) M-ATH (i.e., automation of the first two type of hunts, using AI and machine learning). M-ATH includes ML-assisted adaptive thresholding and outlier handling, for improved alerts (i.e., faster alerting with fewer false positives and false negatives).
- “Don’t be a SOAR loser!” Okay, that’s what one of the Splunk speakers said at .conf23. By that, he was referring to being a winner with Splunk SOAR: Security Orchestration, Automation and Response. SOAR orchestrates, prioritizes, and automates security teams (SecOps) workflows and tasks, enabling more accurate, more complete, smarter, and faster response to security incidents. As Splunk says, “Automate so you can innovate.” Isn’t that always a business truth? If you can free your analyst teams to think outside the box, hypothesize, innovate, and test new methods and solutions, then that is the sure path to being a SAFE (Security Analytics For the Enterprise) winner: soar with SOAR! While SIEM (Security Information and Event Management) aims to manage the data flows, logging, audits, alerted events, and incident responses, SOAR automates these security activities (using machine learning and AI), monitors the data and events for anomalous behaviors, classifies (prioritizes) the events, and then orchestrates optimized security operations and incident responses (using playbooks).
- Saving my best two .conf23 learning moments for last, first up is Splunk Edge Hub. This is a physical device, in the IoT (Internet of Things) family of sensors, that collects and streams data from the edge (i.e., from edge devices, cameras, streaming data sources, monitoring systems, and sensors of all types) into Splunk systems that go to work on those data: security operations, anomaly detection, event classification, trend detection, drift detection, behavior detection, and any other edge application that requires monitoring and observability, with an injection of machine learning and AI for intelligent data understanding, classification, prioritization, optimization, and automation. Since business thrives at the edge (through insights discovery and actionable analytics at the point—time and place—of data collection), an edge hub is just what a business needs to mitigate risk, ensure visibility, escalate incidents for review, optimize the operational response, and monitor the associated activities (causes and effects).
- Splunk AI Assistant – Boom! This is the brilliant and innovative introduction of an AI assistant into Splunk products, services, and user workflows. This includes the latest and best of AI — generative AI and natural language interfaces integrated within the Splunk platform. This product release most definitely enables and “catalyzes digital resilience in cybersecurity and observability.” This is not just a product release. It is a “way of life” and “a way of doing business” with Splunk products and services. AI is not just a tacked-on feature, but it is a fundamental characteristic and property of those products’ features. Splunk AI increases productivity, efficiency, effectiveness, accuracy, completeness, reliability, and (yes!) resilience across all enterprise SecOps, ITOps, and AIOps functions, tasks, and workflows that are powered by Splunk. Generative AI enables the Splunk SecOps and ITOps tasks, workflows, processes, insights, alerts, and recommended actions to be domain-specific and customer-specific. It automatically detects anomalies and focuses attention where it’s needed most, for that business in that domain, while providing full control and transparency on which data and how data are used to train the AI, and how much control is assigned to the AI (by maintaining “human in the loop” functionality). With regard to the natural language features, Splunk AI Assistant leverages generative AI to provide an interactive chat experience and helps users create SPL (Splunk Processing Language) queries using natural language. This feature not only improves time-to-value, but it “helps make SPL more accessible, further democratizing an organization’s access to, and insights from, its data” – and that includes automated recommendations to the user for “next best action”, which is a great learning prompt for new Splunk users and SecOps beginners.
For a peek into my peak real-time experiences at .conf23, see my #splunkconf23 social thread on Twitter at https://bit.ly/3DjI5NU. Actually, go there and explore, because there is so much more to see there than I could cover in this one report.
Closing thoughts – AI (particularly generative AI) has been the hottest tech topic of the year, and Splunk .conf23 did not disappoint in their coverage of this topic. The agendas for some events are filled with generic descriptions that sing the praises of generative AI. This Splunk event .conf23 provided something far more beneficial and practical: they presented demonstrably valuable business applications of generative AI embedded in Splunk products, which deliver a convincing Splunk-specific productivity enhancer for new and existing users of Splunk products. When the tech hype train is moving as fast as it has been this year, it is hard for a business to quickly innovate, incorporate, and deliver substantially new features that use the new tech within their legacy products and services, but Splunk has done so, with top marks for those achievements.
Disclaimer: I was compensated as an independent freelance media influencer for my participation at the conference and for this article. The opinions expressed here are entirely my own and do not represent those of Splunk or of any Splunk partners. Any misrepresentations of the products and services mentioned in my statements are entirely my own responsibility. Nothing here should be construed as an offer to sell or as financial advice of any kind. My comments are entirely of a technical nature, focused on the technical capabilities of the items mentioned in the article.