
The late great baseball legend Yogi Berra was credited with saying this gem: “The future ain’t what it used to be.” In the context of big data analytics, I am now inclined to believe that Yogi was very insightful — his statement is an excellent description of Prescriptive Analytics.
Prescriptive Analytics goes beyond Descriptive and Predictive Analytics in the maturity framework of analytics. “Descriptive” analytics delivers hindsight (telling you what did happen, by generating reports from your databases), and “predictive” delivers foresight (telling you what will happen, through machine learning algorithms). Going one better, “prescriptive” delivers insight: discovering so much about your application domain (from your collection of big data and information resources, through data science and predictive models) that you are now able to take the actions (e.g., set the conditions and parameters) needed to achieve a prescribed (better, optimal, desired) outcome.
So, if predictive analytics can use historical training data sets to tell us what will happen in the future (e.g., which products a customer will buy; where and when your supply chain will need replenishing; which vehicles in your corporate fleet will need repairs; which machines in your manufacturing plant will need maintenance; or which servers in your data center will fail), then prescriptive analytics can alter that future (i.e., the future ain’t what it used to be).
When dealing with large high-variety data sets, with many features and measured attributes, it is often difficult to build accurate models that are generally useful under a variety of conditions and that capture all of the complexities of the response functions and explanatory variables within your business application. In such cases, fast automatic modeling tools are needed. These tools can help to identify the minimum viable feature set for accurate predictive and prescriptive modeling. For this purpose, I recommend that you check out the analytics solutions from the fast automatic modeling folks at http://soft10ware.com/.
The Soft10 software package is trained to observe quickly and report automatically the most significant, informative and explanatory dependencies in your data. Those capabilities are the “secret sauce” in insightful prescriptive analytics, and they coincide nicely with another insightful quote from Yogi Berra: “You can observe a lot by just watching.”
(Read the full blog at: https://www.linkedin.com/pulse/prescriptive-analytics-future-aint-what-used-kirk-borne)
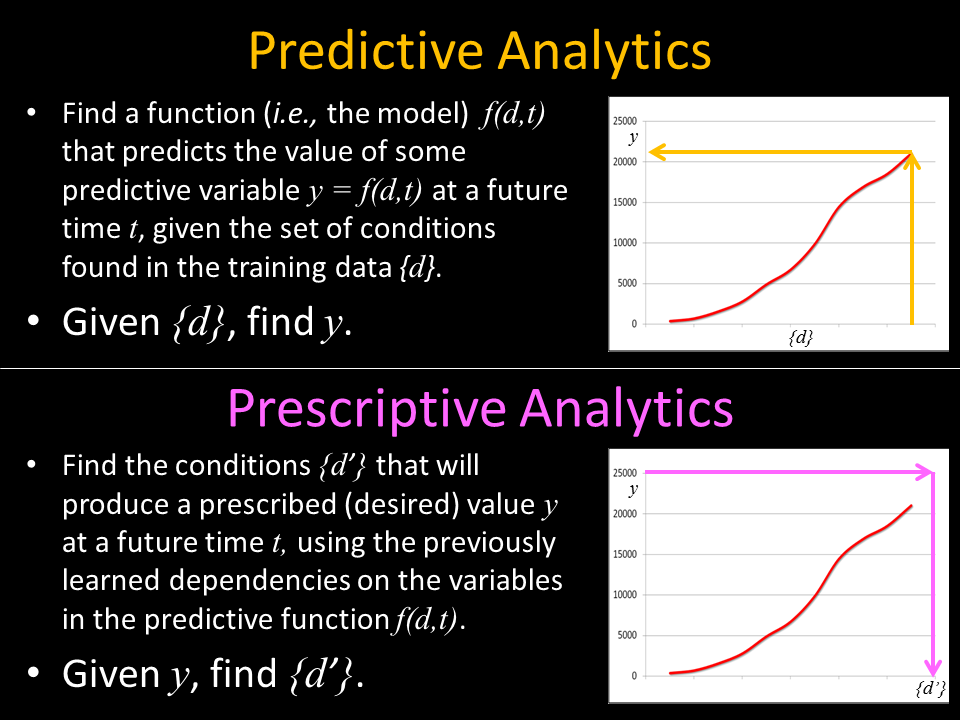
Predictive Analytics (given X, find Y) vs. Prescriptive Analytics (given Y, find X)
Follow Kirk Borne on Twitter @KirkDBorne





