Diversity in data is one of the three defining characteristics of big data — high data variety — along with high data volume and high velocity. We discussed the power and value of high-variety data in a previous article: “The Five Important D’s of Big Data Variety” We won’t repeat those lessons here, but we focus specifically on the bias-busting power of high-variety data, which was actually the last of the five D’s mentioned in the earlier article: Decreased model bias.
Here, we broaden our meaning of “bias” to go beyond model bias, which has the technical statistical meaning of “underfitting”, which essentially means that there is more information and structure in the data than our model has captured. In the current context, we apply a broader definition of bias: lacking a neutral viewpoint, or having a viewpoint that is partial. We will call this natural bias, since the examples can be considered as “naturally occurring” without obvious intent. This article does not elaborate on personal bias (which might be intentional), though the cause for that kind of prejudice is essentially the same: not considering and taking into account the full knowledge and understanding of the person or entity that is the subject of the bias.
We wrote a longer complete version of this article here: “Busting Bias with More Data Variety” at the Western Digital DataMakesPossible.com blog site.
In that full version of this article, we go on to describe several examples of natural bias and then to present a recommended bias-busting remedy for those of us working in the realm of data science. We refer to that remedy as the CCDI data & analytics strategy: Collect, Curate, Differentiate, and Innovate.
Here is one of the four examples of natural bias that you will find in the longer, complete version of the article:
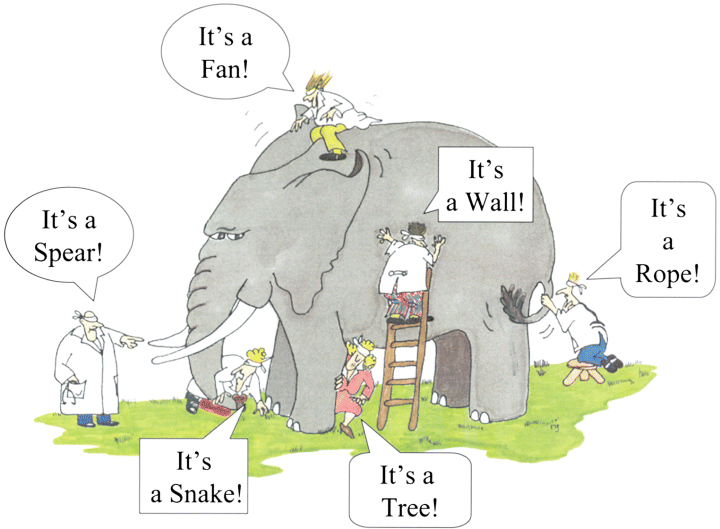
- An example of natural bias comes from a famous cartoon. The cartoon shows three or more blind men (or blindfolded men) feeling an elephant. They each feel a different aspect of the elephant: the tail, a tusk, an ear, the body, a leg — and consequently they each offer a different interpretation of what they believe this thing is (which they cannot see). They say it might be a rope (the tail), or a spear (the tusk), or a large fan (the ear), or a wall (the body), or a tree trunk (the leg). Only after the blindfolds are removed (or an explanation is given) do they finally “see” the full truth of this large complex reality. It has many different features, facets, and characteristics. Focusing on only one of those features and insisting that this partial view describes the whole thing would be foolish. We have similar complex systems in our organizations, whether it is the human body (in healthcare), or our population of customers (in marketing), or the Earth (in climate science), or different components in a complex system (like a manufacturing facility), or our students (in a classroom), or whatever. Unless we break down the silos and start sharing our data (insights) about all the dimensions, viewpoints, and perspectives of our complex system, we will consequently be drawn into biased conclusions and actions, and thus miss the key insights that enable us to understand the wonderful complexity and diversity of the thing in its entirety. Integrating the many data sources enables us to arrive at the “single correct view” of the thing: the 360 view!