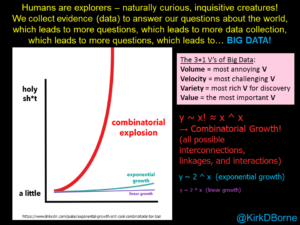
The big change in every industry – energy included – is the sensoring of the world. We have put sensors on just about everything, and that’s definitely true in the energy sector, whether it’s in electricity, oil and gas, supply chain and manufacturing, or even customer interaction.
We call that big data, which people sometimes take to mean as big volume, but I like to think of as big value. Because with all this information, we can understand how our systems work – and put them to better use to create greater value for our business.
Prescriptive models
There is greater insight than ever before into how energy is distributed, both in the course of the day and across specific locations. In NASA, we tracked potential ‘killer asteroids’ – asteroids that have the potential to do serious damage to our earth.
In the energy industry that increased insight will help when averting its own disasters, or ‘killer asteroids’. Both predictive and prescriptive models are particularly useful here, for predicting future outcomes and for prescribing different (better, optimal) outcomes: if enough data are collected from factors such as the environment, devices used, and contextual information such as weather patterns or energy usage, models now know how to set the user parameters to prevent disaster.
On an energy grid, if a bad outcome is upcoming, conditions can be set to prevent machine failure, whether through reducing the operating temperature or speed, or increasing the frequency of on/off cycles.
Digital twins
An exciting proposition for the industrial sector is the digital twin, a full Computer-Aided Design (CAD) model of any device that can be run alongside its original to track behaviour and identify the cause of any failures. In the energy industry, this could be a digital replica of an offshore wind turbine, for example, monitoring power usage, production and efficiencies, and replaying any anomalies to identify their cause.
Crowdsourcing
When I was at NASA, we worked with scientists worldwide to create an online web portal called Zooniverse that presents large data collections to the public, enabling everyone to contribute to scientific discovery in datasets that are too large for the science teams to explore by themselves.
With the mountains of data we had it might take years, even centuries, to look through. But if you put it online and create an interesting enough challenge around that data, people across the world are going to volunteer their time in the name of scientific research.
We had some incredible results from this crowdsourcing mission. A Dutch schoolteacher called Hanny van Arkel discovered a strange green object while she was looking through images, which turned out to be an entirely new type of astronomical object (and is now named after her).
If I was to hypothesize how you could similarly crowdsource data in the energy sector, perhaps you could have people look at data prior to blackouts. There could be a pattern to the outage, or they could identify places where the power stays on during these blackouts – such as schools or grocery stores – which could be pinpointed on an app so people could use them when there are cuts.
Move beyond reporting
Energy industry executives should be interested in big data, because it allows them to look at all aspects of their business. I have conversations with publicly traded companies who only report on an annual or quarterly basis. I understand this is a regulatory requirement, but it seems to me to be only acting in hindsight.
You can’t drive a vehicle by looking in the rear-view mirror. You have to understand what’s coming, and the only way you can do that is by taking in all the information that is available to you: from the child playing on the street beside the road, to the truck two cars ahead.
Big data can deal with hindsight – events that have happened in the past; oversight – events happening now; and foresight – events happening in the future. And prescriptive modelling gives insight into all of these events. At a time where the global energy industry is undergoing huge change, don’t we need that forward-looking view of the rich information embedded within our big data reservoirs?
Summary
Therefore, the energy industry can benefit from these four approaches (prescriptive modelling, digital twinning, crowdsourcing, and moving beyond reporting) as ways to manage the digital disruption and the flood of new data coming from sensors everywhere. Industry leaders used to encourage organizations to adopt certain products or methodologies to help their data analytics move at the speed of business. I believe now that this is not a viable approach. What you really need are solutions that can help your business move at the speed of your data!
———————–
NOTE: This post was originally published at https://www.linkedin.com/pulse/four-ways-harness-big-data-energy-sector-kirk-borne/