When I was young, my dad told me about an incident that he experienced at work. He was a US Air Force officer. On that particular day, there was an unannounced (surprise) drill – a simulated national defense emergency. Though it was just a drill, it was still important to get it done right and efficiently. One of his responsibilities was to contact certain high-ranking officers and communicate with them about the situation (in this case, the simulated emergency). He told me that, in one case, he was able to make contact by phone with one of those top officers within 20 seconds of the start of the drill. If that guy had been in the office or in one of the major facilities, then those 20 seconds would not have been surprising. But it turns out that it was that guy’s day off and he was out playing golf. This was the early 1970’s – hence, no mobile phones, no cell towers, and no internet in your pocket.
How was it possible to find this guy in the middle of some golf course and have him on the phone within 20 seconds in that era? From my young person’s perspective, it was a miracle! Or maybe it was magic. As Sir Arthur C. Clarke said, “Any sufficiently advanced technology is indistinguishable from magic.” So, what enabled this “magic” in the early 1970’s? The answer: satellite phones! The high-ranking officer was required to have such a device with him at all times (either in his possession or to have an assistant accompany him nearby with that device available at a moment’s notice).
A connected world—with a digital divide
Now, fast-forward to the current digital world – for most of us today, the expectation seems to be that we all should have easy access to ubiquitous mobile phones, cell towers, high-speed broadband networks, and the internet at all times! However, though that may be the rule for most of us, it is not the norm for everyone! There are plenty of exceptions to the rule, especially in those areas of the world that fall in the gaps of today’s digital service providers: underdeveloped countries, remote regions of developed countries, regions in which natural disasters or national emergencies have lost ties to those digital services (including national defense emergencies), and massive public events that attract literally billions of people in-person and online to one specific geolocation (which definitely cannot be handled by the standard placement and distribution of cell towers).
Those exceptions to the rule are not rare. In fact, they are quite common. It is imperative that something be done about this, to close those digital gaps, to bring the benefits of digital services to all, and to boost the global digital business value chain. If we cannot make these technologies available for everyone, we risk perpetuating a divide between the haves and have-nots.
Promoting connectivity on a global scale
There is a company that is addressing this “digital divide” and this data-intensive digital connectivity imperative on a global scale. SES is getting it done with major innovations and 21st century technological upgrades to critical satellite communications, going far beyond the traditional satellite technology of the past century.
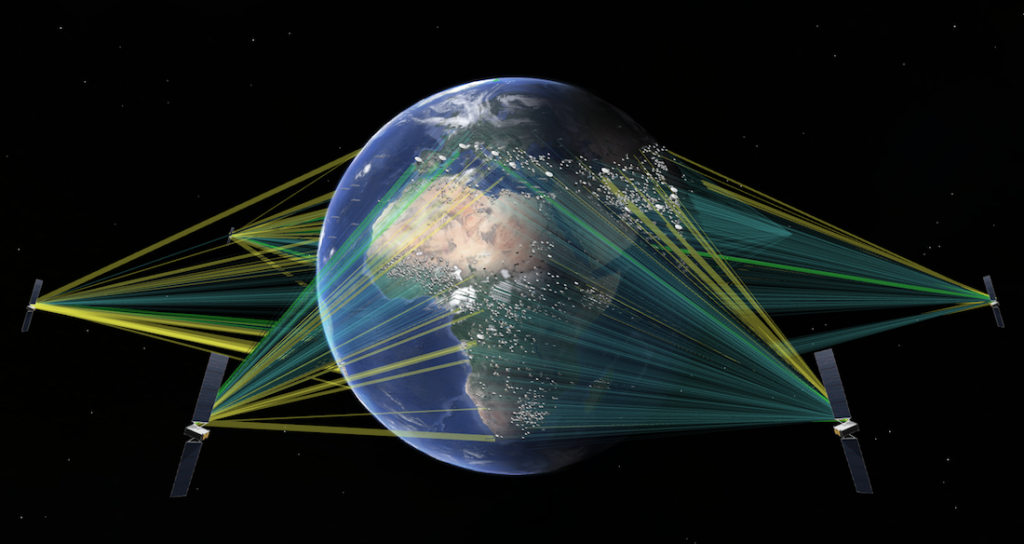
But this isn’t my dad’s satellite phone service. The SES connectivity system supplies digital (video and data) connectivity worldwide to broadcasters, mobile network operators, fixed network operators, digital content providers, internet service providers, and organizations of all sorts (government agencies, businesses, and other institutions). SES satellites deliver high-speed, high-volume, broadband, and effectively ubiquitous digital access for these organizations over nearly the entire planet Earth.
When I say, “nearly the entire planet”, I mean 96% of the population. Over seven and a half billion people around the world are now a fraction of a second from contact anywhere, anytime. I believe that we can all agree that a “fraction of a second” (e.g., 150 milliseconds of satellite latency over large areas) is much better than 20 seconds – in fact, over 100X better than the 1970’s counterparts!
Furthermore, when the situation demands it (such as a major event in a specific location that is attracting a billion+ digital viewers, or a localized natural disaster requiring massive global deployment of services to that spot), these satellites can be programmed to focus their beam and full capabilities on transmitting massive digital content in and out of that tiny area.
The fast, global, ubiquitous digital access that we are describing is nothing like the crackly satellite phone conversations of the past (have you seen this in the old movies?). We are talking about smooth and faultless streaming video, crisp and clean phone calls, information-intensive online meetings, error-free data-sharing, and nearly instantaneous social media accesses and interactions by vast numbers of people (think World Cup Finals, or a live concert by top music artists for a global cause). Let’s not forget the time-critical demands of digital business and digital government that require instant access to data-intensive cloud-based data and data services! That’s a massive digital enterprise requirement for a massive number of organizations, not just an entertainment requirement for the masses.
An in-person visit to SES in Virginia
SES is headquartered in Luxembourg, with facilities around the world, including Manassas Virginia, where I visited a few weeks ago when I met with Nihar Shah, Head of Strategy and Market Intelligence for SES. In addition to a fun wide-ranging fact-filled chat with Nihar, there was a lot more that I learned about SES in that short visit. It was a great pleasure for me (who spent nearly 20 years working at NASA) to see the satellite operations center, the “big box of electronics” that is placed on-site at major events (including sporting events, for my and your favorite sports), and the dedicated SES staff. I learned how SES has deployed and operates one of the world’s largest satellite constellations, including MEO (Medium Earth Orbit) satellites and GEO (Geosynchronous Earth Orbit) satellites – different orbits for different requirements, plus an incredible technology stack that manages the communications hand-offs between the MEO satellites as they fly fast over any given location. What did we say earlier about “any sufficiently advanced technology”? It certainly is not magic when it delivers real global benefits and generates significant business value.
To top off this experience, I was immediately impressed when I walked in the front door of the SES Global Operations Center, not only because of the welcoming staff, but also because I saw the company mission statement front and center as I entered the lobby. I am a huge fan of meaningful, believable, inspirational, and actionable mission statements. SES might easily have one of the best mission statements that I have seen – and that’s not only because they refer to their statement of purpose as their “North Star”, which suits me (as an astronomer) very well. The statement reads: “We do the extraordinary in space, to deliver amazing experiences everywhere on Earth.” (Note: see me and Nihar in the attached photo below, with the SES statement of purpose.)
I look forward to learning more about SES. You too can learn more about SES and their global content connectivity solutions at https://www.ses.com/.