I recently attended the Splunk .conf22 conference. While the event was live in-person in Las Vegas, I attended virtually from my home office. Consequently I missed the incredible in-person experience of the brilliant speakers on the main stage, the technodazzle of 100’s of exhibitors’ offerings in the exhibit arena, and the smooth hip hop sounds from the special guest entertainer — guess who?
What I missed in-person was more than compensated for by the incredible online presentations by Splunk leaders, developers, and customers. If you have ever attended a major expo at one of the major Vegas hotels, you know that there is a lot of walking between different sessions — literally, miles of walking per day. That’s good for you, but it often means that you don’t attend all of the sessions that you would like because of the requisite rushing from venue to venue. None of that was necessary on the Splunk .conf22 virtual conference platform. I was able to see a lot, learn a lot, be impressed a lot, and ponder a lot about all of the wonderful features, functionalities, and future plans for the Splunk platform.
One of the first major attractions for me to attend this event is found in the primary descriptor of the Splunk Platform — it is appropriately called the Splunk Observability Cloud, which includes an impressive suite of Observability and Monitoring products and services. I have written and spoken frequently and passionately about Observability in the past couple of years. For example, I wrote this in 2021:
“Observability emerged as one of the hottest and (for me) most exciting developments of the year. Do not confuse observability with monitoring (specifically, with IT monitoring). The key difference is this: monitoring is what you do, and observability is why you do it. Observability is a business strategy: what you monitor, why you monitor it, what you intend to learn from it, how it will be used, and how it will contribute to business objectives and mission success. But the power, value, and imperative of observability does not stop there. Observability meets AI – it is part of the complete AIOps package: ‘keeping an eye on the AI.’ Observability delivers actionable insights, context-enriched data sets, early warning alert generation, root cause visibility, active performance monitoring, predictive and prescriptive incident management, real-time operational deviation detection (6-Sigma never had it so good!), tight coupling of cyber-physical systems, digital twinning of almost anything in the enterprise, and more. And the goodness doesn’t stop there.”
Continue reading my thoughts on Observability at http://rocketdatascience.org/?p=1589
The dominant references everywhere to Observability was just the start of awesome brain food offered at Splunk’s .conf22 event. Here is a list of my top moments, learnings, and musings from this year’s Splunk .conf:
- Observability for Unified Security with AI (Artificial Intelligence) and Machine Learning on the Splunk platform empowers enterprises to operationalize data for use-case-specific functionality across shared datasets. (Reference)
- The latest updates to the Splunk platform address the complexities of multi-cloud and hybrid environments, enabling cybersecurity and network big data functions (e.g., log analytics and anomaly detection) across distributed data sources and diverse enterprise IT infrastructure resources. (Reference)
- Splunk Enterprise 9.0 is here, now! Explore and test-drive it (with a free trial) here.
- The new Splunk Enterprise 9.0 release enables DevSecOps users to gain more insights from Observability data with Federated Search, with the ability to correlate ops with security alerts, and with Edge Management, all in one platform. (Reference)
- Security information and event management (SIEM) on the Splunk platform is enhanced with end-to-end visibility and platform extensibility, with machine learning and automation (AIOps), with risk-based alerting, and with Federated Search (i.e., Observability on-demand). (Reference)
- Customer success story: As a customer-obsessed bank with ultra-rapid growth, Nubank turned to Splunk to optimize data flows, analytics applications, customer support functions, and insights-obsessed IT monitoring. (Reference)
- The key characteristics of the Splunk Observability Cloud are Resilience, Security, Scalability, and EXTENSIBILITY. The latter specifically refers to the ease in which developers can extend Splunk’s capabilities to other apps, applying their AIOps and DevSecOps best practices and principles! Developers can start here.
- The Splunk Observability Cloud has many functions for data-intensive IT, Security, and Network operations, including Anomaly Detection Service, Federated Search, Synthetic Monitoring, Incident Intelligence, and much more. Synthetic monitoring is essentially digital twinning of your network and IT environment, providing insights through simulated risks, attacks, and anomalies via predictive and prescriptive modeling. [Reference]
- Splunk Observability Cloud’s Federated Search capability activates search and analytics regardless of where your data lives — on-site, in the cloud, or from a third party. (Reference)
- The new release of the Splunk Data Manager provides a simple, modern, automated experience of data ingest for Splunk Cloud admins, which reduces the time it takes to configure data collection (from hours/days to minutes). (Reference)
- Splunk works on data, data, data, but the focus is always on customer, customer, customer — because delivering best outcomes for customers is job #1. Explore Splunk’s amazing Partner ecosystem (Partnerverse) and the impressive catalog of partners’ solutions here.
- Splunk .conf22 Invites Organizations to Unlock Innovation With Data.
In summary, here is my list of key words and topics that illustrate the diverse capabilities and value-packed features of the Splunk Observability Cloud Platform that I learned about at the .conf22 event:
– Anomaly Detection Assistant
– Risk-based Alerting (powered by AI and Machine Learning scoring algorithms)
– Federated Search (Observability on-demand)
– End-to-End Visibility
– Platform Extensibility
– Massive(!) Scalability of the Splunk Observability Cloud (to billions of transactions per day)
– Insights-obsessed Monitoring (“We don’t need more information. We need more insights.”)
– APIs in Action (to Turn Data into Doing™)
– Splunk Incident Intelligence
– Synthetic Monitoring (Digital Twin of Network/IT infrastructure)
– Splunk Data Manager
– The Splunk Partner Universe (Partnerverse)
My closing thought — Cybersecurity is basically Data Analytics: detection, prediction, prescription, and optimizing for unpredictability. This is what Splunk lives for!
Follow me on LinkedIn here and on Twitter at @KirkDBorne.
Disclaimer: I was compensated as an independent freelance media influencer for my participation at the conference and for this article. The opinions expressed here are entirely my own and do not represent those of Splunk or of any Splunk partners. Any misrepresentations of the products and services mentioned in my statements are entirely my own responsibility. Nothing here should be construed as an offer to sell or as financial advice of any kind. My comments are entirely of a technical nature, focused on the technical capabilities of the items mentioned in the article.
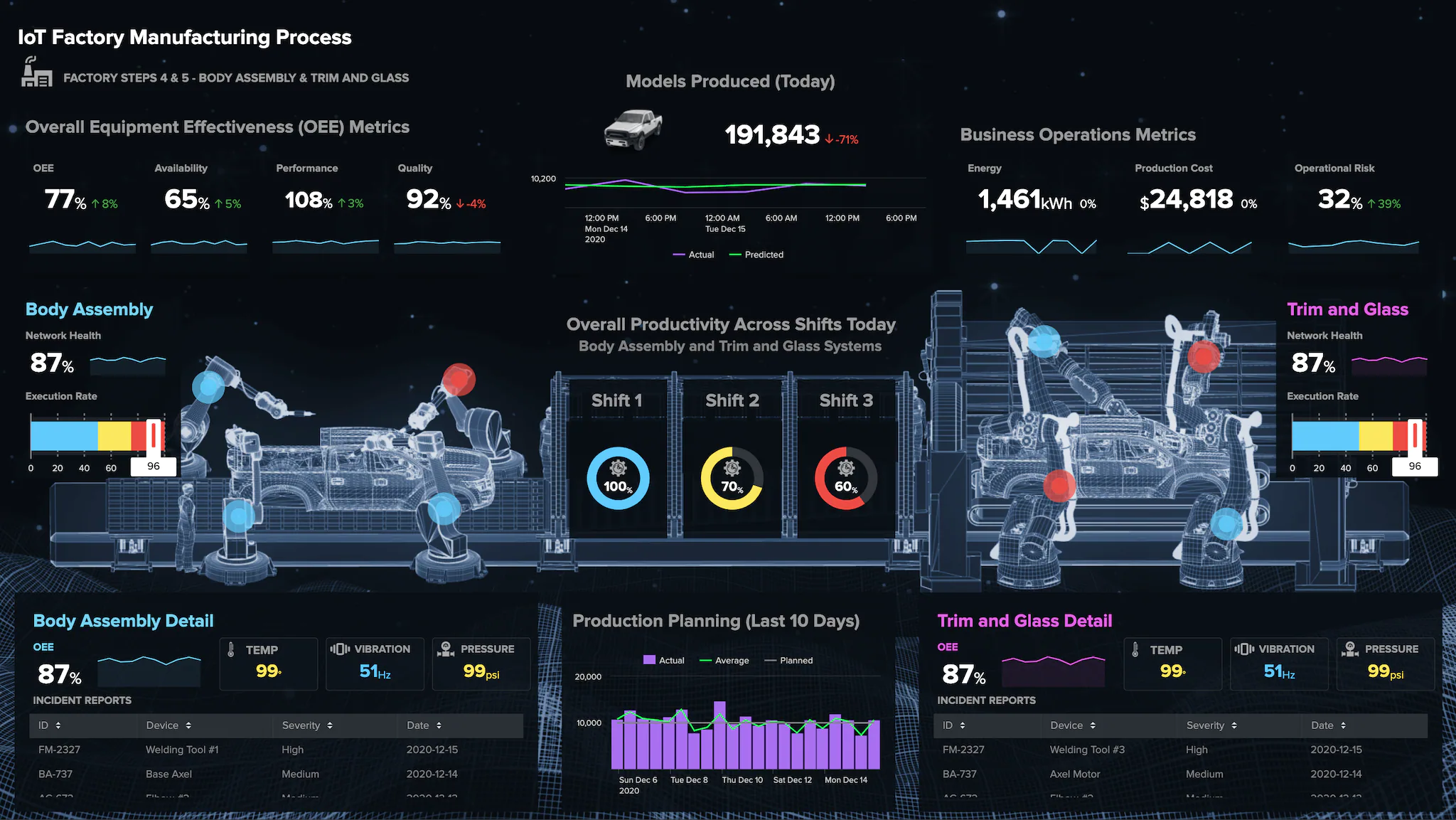
Source: https://www.splunk.com/en_us/products/splunk-cloud-platform.html